目录
Map介绍
内存模型
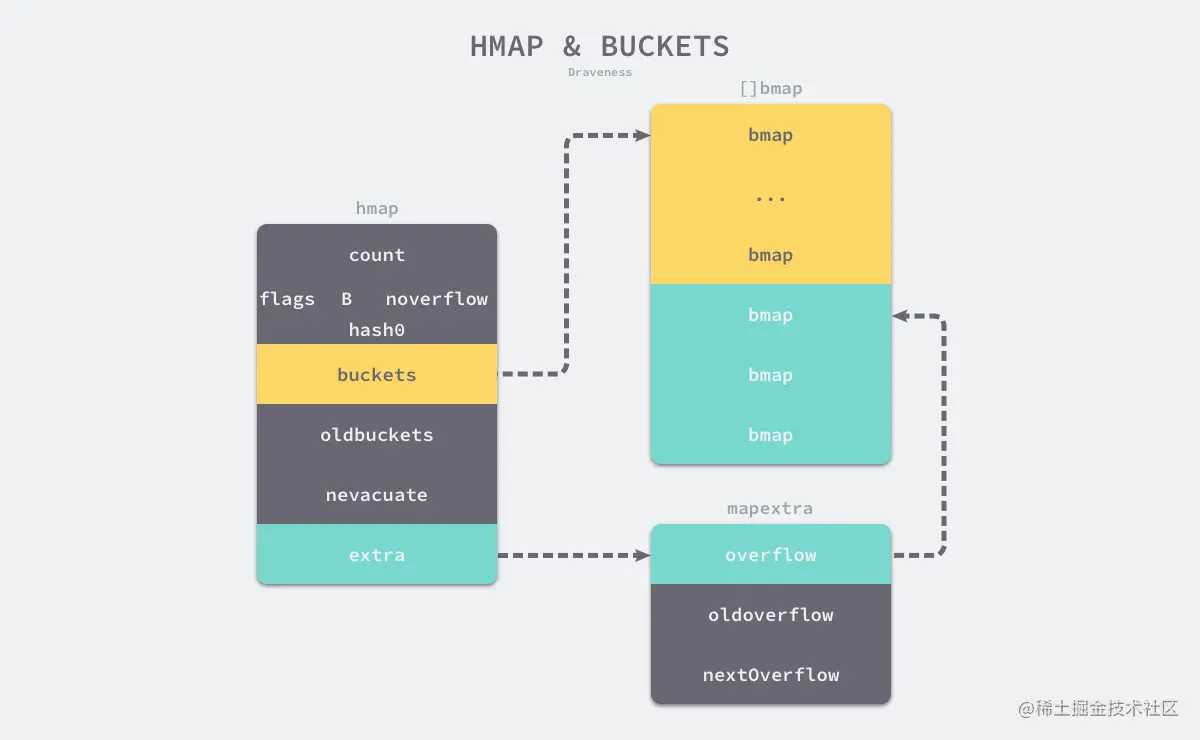
golangtype hmap struct { count int flags uint8 // buckets 的对数 B uint8 // overflow 的 bucket近似数 noverflow // 计算key的哈希的时候会传入哈希函数 hash0 uint32 // 指向buckets数组,如果元素个数为0,就为nil buckets unsafe.Pointer // 扩容的时候,buckets长度会是oldbuckets的两倍 oldbuckets unsafe.Pointer // 之时扩容进度,小于此地址的buckets迁移完成 nevacuate uintptr extra *mapextra }
buckets的数组的长度是2^B,bucket里面存储了key和value
buckets是指针,指向了一个结构体数组,元素类型bmap
golangtype bmap struct { tophash [bucketCnt]uint8 }
这是表面的结构,编译期间会动态创建为
golangtype bmap struct { topbits [8]uint8 keys [8]keytype elems [8]elemtype overflow uintptr }
bmap就是桶,一个桶里面最多装有8个key,这些key是经过hash计算后结果属于同一类的,在桶内又会根据key计算出来的hash值的高8位来决定key到底落入桶内的哪个位置
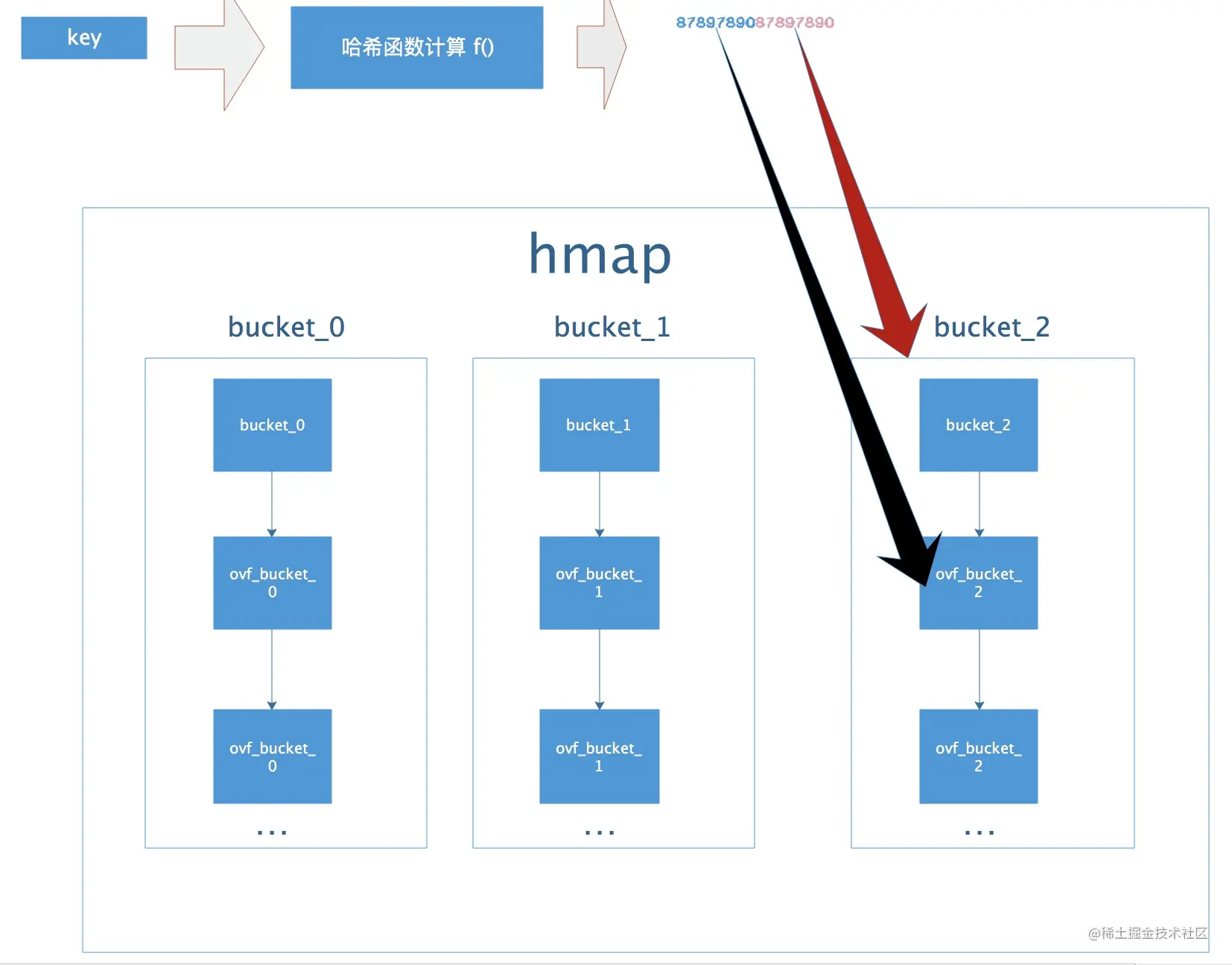
或者说,buckets是指向一个桶数组,每个桶数组中的桶,都是一个bucket链表,然后每次对key进行哈希运算,并且低8位是选择在哪个桶中,而高八位,是存储在tophash里的,为了加快比较速率,因为比较tophash值会比比较键快,比较键需要逐个字节进行比较,而tophash可以直接比较,且存储开销要比存储完整的键值对小
tophash不是减少比较次数,而是加快时间
map扩容
判断扩容的条件,就是哈希表中的加载因子
Golang中的map的加载因子的公示是:map长度/2^B,阈值6.5,B可以理解位已扩容的次数
当map的长度增长到大于加载因子所需的map长度时,Go语言就会产生一个新的bucket数组
扩容的时候,会利用oldbucket,把旧的bucket数组移到该字段,而不是将旧的数组中的元素立刻移到新的bucket中,而是只有当访问到具体某个bucket时,才会转移数据
删除元素
查找key,计算key的hash值,利用低B位找到对应的桶,遍历桶中元素的tophash,如果tophash值相同,对比key,如果key也相同,重置key-value为nil,tophash为1(标记元素为空)
遍历
map的遍历是无序的,会通过种子随机选择一个bucket和一个offset进行遍历
本文作者:Malyue
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!