目录
八股
Golang调度器
调度器的产生是为了并发执行,否则在原先单进程执行的情况是不需要并发调度的,按顺序即可,而多线程/多协程的时代则产生了该需求,虽然看似按时间片来进行进程/协程的调度执行很美好,但是实际上去做的话需要考虑很多的东西,最明显的就是同步冲突的问题(锁,资源竞争)
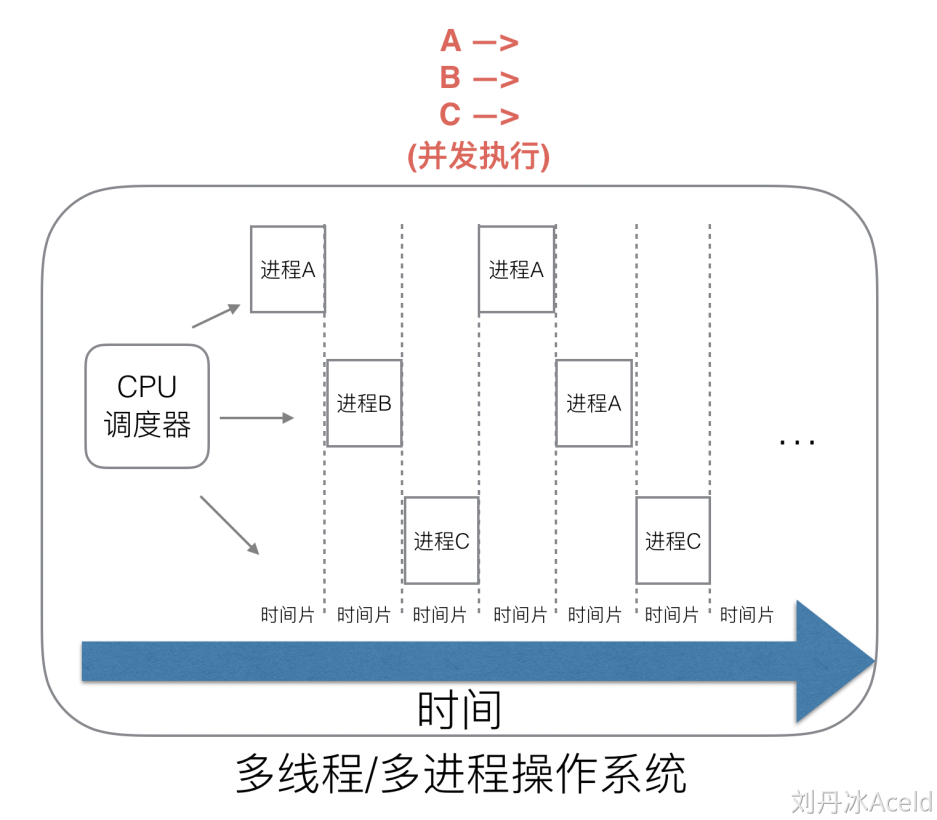
而且虽然多线程/进程提高了系统的并发能力,但是在当前高并发场景下,为每个任务都创建一个线程是不现实的,会消耗大量的内存(进程虚拟内存为4GB,线程也需要4MB),所以高并发情况下会导致高内存占用以及调度的高消耗CPU
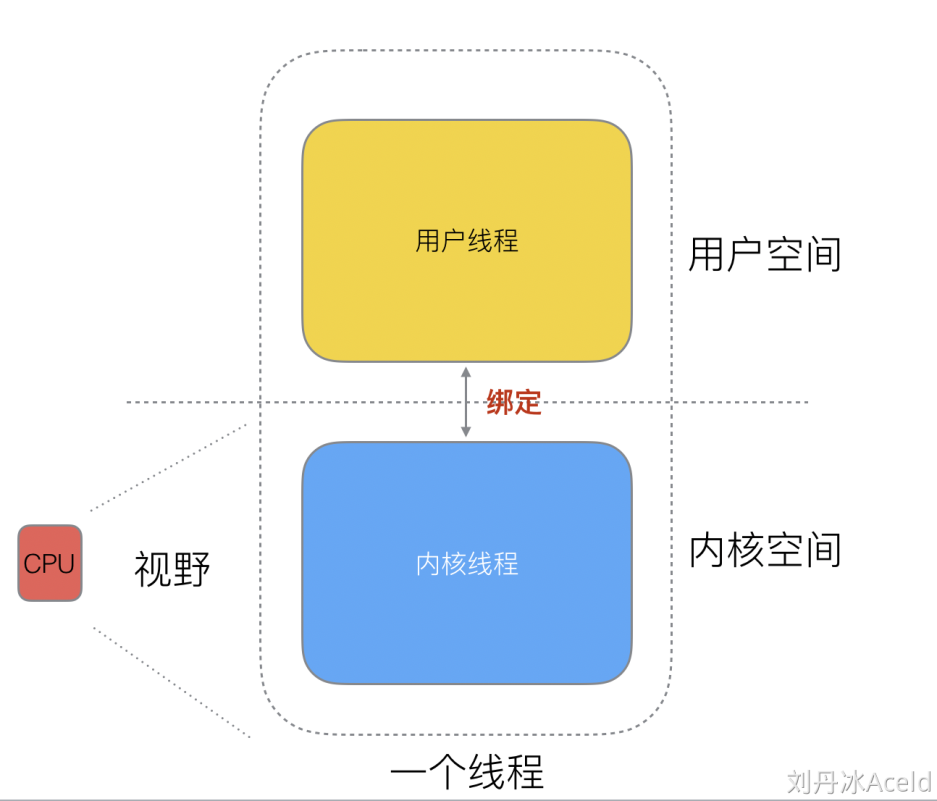
我们又知道,一个线程分为"内核态"/"线程态"和"用户态"两种线程,一个用户态必须绑定一个内存态,而对于执行调度的CPU来说,它是对用户态线程无感知的,它只知道它运行着一个内核态线程(Linux的PCB进程控制块),而人们又对两者进行了一次区分,将用户态的称为协程
协程和线程的三种映射关系
- N:1关系
N个协程绑定1个线程
优点:协程在用户态即可切换,不需要切换到内核态,这样的切换十分方便快捷
缺点:若一个协程阻塞,则会导致本线程阻塞,本线程的其他协程都无法执行了
- 1:1关系
优点:容易实现,不存在N:1的缺点
缺点:每次协程的创建删除切换的代价,都是CPU来完成,代价较大
- M : N关系
实现最为复杂,结合了以上两种关系
协程跟线程是有区别的,线程由CPU调度,是抢占式的,协程由用户态调度,是协作式的,一个协程让出CPU后,才执行下一个协程。
Go语言对于并发的支持就比较好,使用了goroutine和channel,前者是协程的概念,将一组可复用的函数运行在一组协程之上,即使有协程阻塞,该线程的其他协程也可以被调度而转移到其他线程上运行
在Go中,协程十分轻量,一个Goroutine只占几KB,使得可以支持大量的goroutine,而且如果需要更多内存,runtime会自动分配
被废弃的调度器
首先了解一下golang最开始的调度器设计,2012年就被废弃使用新的了,我们先了解一下。
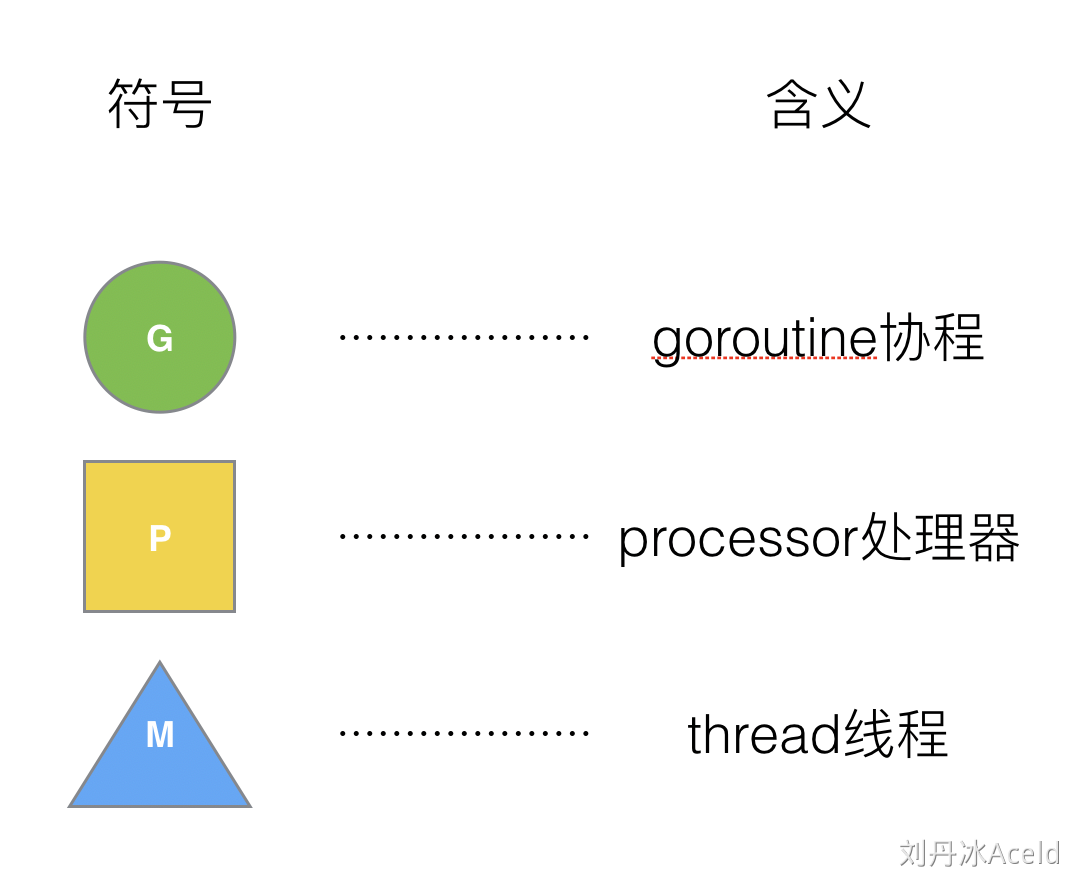
两个最基本的概念
G - goroutine
M - Thread
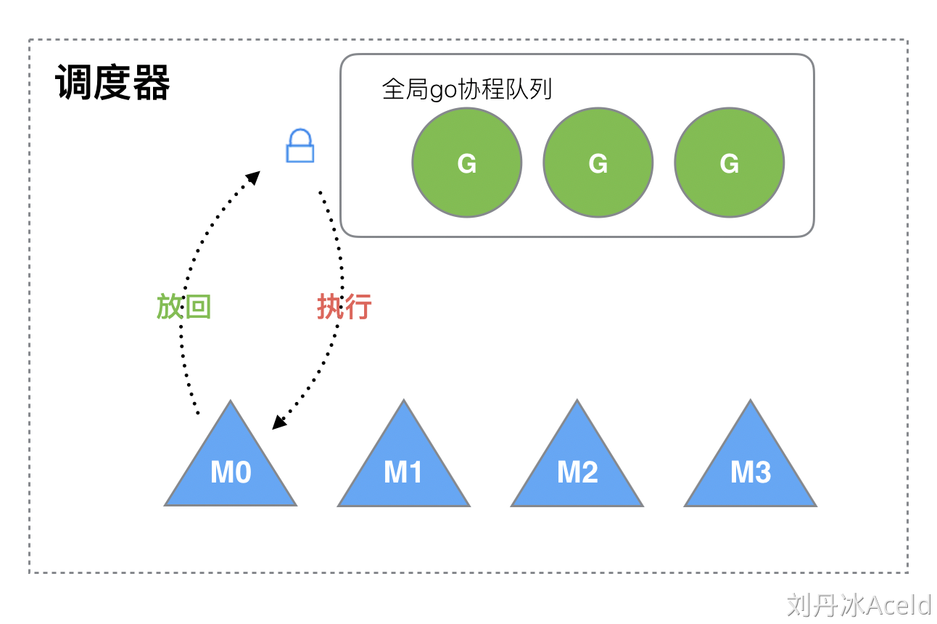
其实就是会有一个全局goroutine队列,然后M通过从队列中取出G来进行执行或放回操作,不过由于拥有多个M,所以需要加锁保证互斥/同步,而这样每次调度都需要去获取锁,十分不方便。
缺点:
- 创建、销毁、调度G都需要每个M去获取锁,这样就很容易导致锁竞争,需要等待
- M转移G会造成
延迟和额外的系统负担,比如,当G中包含创建新协程的时候,M创建了G',为了继续执行G,为了继续执行G,需要把G'交给M'执行,也就会使得局部性较差,因为G和G'是相关的,最好也是在M上执行 - 系统调用(CPU在M之间的切换)导致频繁的线程阻塞和取消阻塞操作增加了系统负担
GMP调度模型
相比之前的调度模型,多加了一个P(Processor),P中包含了运行goroutine的资源,如果线程想运行goroutine,必须先去获取P,P中还包含了可运行的G队列
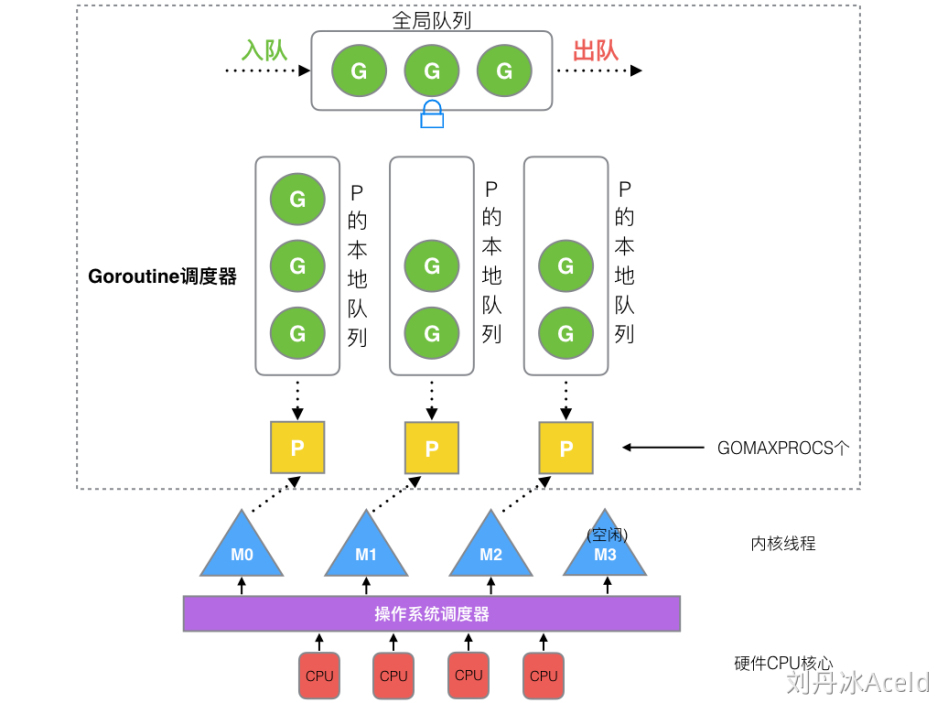
线程是运行goroutine的实体,调度器的功能是把可运行的goroutine分配到工作线程上
- 全局队列:存放等待运行的G
- P的本地队列:每个P都有一个自己的本地队列,存放的是等待运行的G,不超过256个,新建一个G'时,优先加入P的本地队列,如果队列满了,会将一半移动到全局队列,我认为有了这个本地队列可以减少前面所说的锁竞争问题,因为从全局队列中拿的情况变少了
- P列表:
所有的P都在程序启动时创建,并保持在数组中,最多有GOMAXPROCS个 - M:线程想运行任务就得获取P,从P的本地队列获取G,P队列为空时,M会优先从全局队列拿一批G放到P的本地队列中,如果没有再从其他P的本地队列偷一半放到自己的P的本地队列,M运行G,G执行之后,M会从P获取下一个G,不断重复,每个M其实就是代表一个内核线程,OS调度器负责把内核线程分配到CPU的核上执行
- 常见问题
- P的数量
由启动时环境变量$GOMAXPROCS或者是runtime的方法GOMAXPROCS()决定。这意味着在程序执行的任意时刻都只有$GOMAXPROCS个goroutine在同时运行
- M的数量
- go语言本身会设置M的最大数量为10000,但是内核其实很难支持这么多的线程数,所以该限制忽略不计
- runtime/debug中的SetMaxThread方法
- 一个M阻塞了,P会去创建/切换新的M
- 开始时只有一个系统线程来执行程序,并在需要的情况下根据任务分配核CPU负载的变化来创建新的系统线程
- P和M何时创建
- 在确定了P的最大数量后,程序运行时系统就会创建
- 没有足够的M来关联P并运行其中可运行的G时会创建,比如此时所有的M都阻塞了,没有空闲的,而P中还有很多就绪任务,就会去寻找空闲的M,而没有空闲的就会创建新的。
GMP的设计策略
- 复用线程
- 利用并行
- 抢占
- 全局G队列
- 复用线程
避免频繁的创建、销毁线程,而是对线程的复用
- work stealing机制
当本线程无可运行的G时,会从其他线程绑定的P偷取G,而不是就销毁线程,会尽可能的利用创建好的线程
- hand off机制
当本线程因为G进行系统调用阻塞时,线程会主动释放绑定的P,把P转移给其他空闲的线程执行
- 利用并行
GOMAXPROCS设置P的数量,最多有对应该数量的线程分布在多个CPU上同时运行
- 抢占
在coroutine中要等待一个协程主动让出CPU才能执行下一个,但是Go中,一个协程最多占用CPU10ms,防止其他协程被饿死
- 全局G队列
Go语言的调度器优势在于:
- Go语言使用用户空间调度,即线程和goroutine的管理都在用户空间中实现
- M :N模型
- TODO
go func()流程
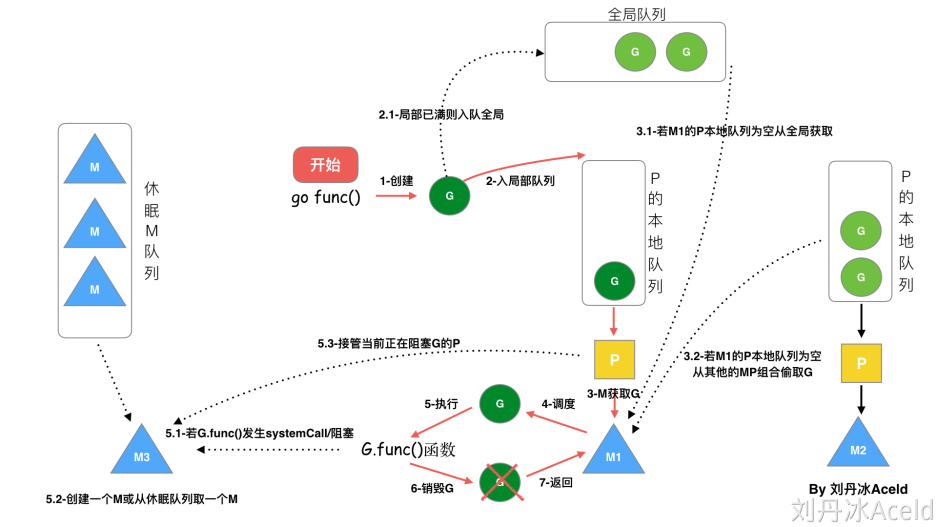
- go func()创建一个goroutine
- 两个存储G的队列,新创建的G会先保存在P的本地队列中,如果P的本地队列满了再去加入全局队列
- G只能运行在M中,一个M必须有一个P,M会从P的本地队列中弹出一个可执行状态的G来执行,如果P的本地队列为空,就会执行work stealing
- 一个M调度G执行的过程是一个循环机制
- 当M执行某一个G时如果发生了syscall或其余阻塞操作,M会阻塞,如果当前有一些G在执行,runtime会把这个线程M从P中摘除,然后再创建一个新的操作系统的线程来(或复用空闲线程)服务P
- 当M系统调用结束时,这个G会尝试获取一个空闲的P执行,并放入这个P的本地队列,如果获取不到P则进入休眠状态,加入到空闲线程中,然后这个G会被放入全局队列中
举例
- M和P的1:1是指的是绑定的,实际上两者数量没有关系,一旦M进入了系统调用,会标记当前的P,然后就会创建一个新的M去绑定P,而结束了系统调用后,会先去尝试获取原先标记的P,如果获取不到就去获取空闲的,如果都没有,则将goroutine标记为可运行状态,加入全局队列,然后M会进入休眠状态
- 创建一个G时,运行的G会尝试去唤醒其他空闲的P和M组合去执行
- 自旋线程-没有G但为运行状态的线程,不断寻找G,出现自旋线程的情况可能就是第二点所说的
- 自旋线程的数量有限制,其实就是受到P最大数量的限制,因为自旋线程必须绑定P
- 新创建的G一般优先放到本地队列中,这也是为了局部性原理
- 如果本地队列已满,会将前一半以及新创建的一起加入全局队列,而且会打乱顺序,打乱顺序是为了防止饿死的情况出现
内存逃逸
什么是内存逃逸?
当编译器无法保证一个变量的生命周期只在函数内部时,它就会认为这个变量逃逸了,需要在堆上分配内存。这样可以保证变量在函数返回后依然有效,不会被栈回收。
简单来说,局部变量通过堆分配和回收,就称为内存逃逸
在程序中,每个函数块都有自己的内存区域用来存储自己的局部变量(内存占用少),返回地址,返回值之类的数据,这一块内存区域有特定的结构和寻址方式,寻址起来很快,开销少,这一块内存地址称为栈,栈是线程级别的,大小在创建的时候已经确定,当变量太大时,会逃逸到堆上,这也称为内存逃逸。
Go语言编译器会自动决定把一个变量放到栈或堆上,编译器会做逃逸分析(escape analysis),当发现变量的作用域没有抛出函数范围,就可以在栈上,反之则必须分配在堆
为什么会有这个呢,我们来看一个代码
C// C #include <stdio.h> int *foo(int arg_val){ int foo_val = 11; return &foo_val; } int main(){ int *main_val = foo(666); printf("%d\n",*main_val); }
这一段用go的逻辑来看,是不是没有什么问题,但是实际上你一旦运行,就会报错,因为外部函数使用了子函数的局部变量,理论上来讲,子函数的foo_val的生命周期早就已经被销毁了
来看一段go代码
golangpackage main func foo(arg_val int) (*int) { var foo_val1 int = 11; var foo_val2 int = 12; var foo_val3 int = 13; var foo_val4 int = 14; var foo_val5 int = 15; //此处循环是防止go编译器将foo优化成inline(内联函数) //如果是内联函数,main调用foo将是原地展开,所以foo_val1-5相当于main作用域的变量 //即使foo_val3发生逃逸,地址与其他也是连续的 for i := 0; i < 5; i++ { println(&arg_val, &foo_val1, &foo_val2, &foo_val3, &foo_val4, &foo_val5) } //返回foo_val3给main函数 return &foo_val3; } func main() { main_val := foo(666) println(*main_val, main_val) }
输出的结果是
shell$ go run pro_2.go 0xc000030758 0xc000030738 0xc000030730 0xc000082000 0xc000030728 0xc000030720 0xc000030758 0xc000030738 0xc000030730 0xc000082000 0xc000030728 0xc000030720 0xc000030758 0xc000030738 0xc000030730 0xc000082000 0xc000030728 0xc000030720 0xc000030758 0xc000030738 0xc000030730 0xc000082000 0xc000030728 0xc000030720 0xc000030758 0xc000030738 0xc000030730 0xc000082000 0xc000030728 0xc000030720 13 0xc000082000
很明显的看出,foo_val3和其他的地址是不连续的,可以用go tool compile -m pro_2.go来查看,也可以看到foo_val3被判断为逃逸变量,放在堆中开辟
new和make的变量所在位置
new和make有什么区分,这是一个常见的八股问题
这两个都是go的内置函数,主要用来创建并分配类型的内存
先看一下new和make的区别
- new
new其实只是分配内存,然后返回一个对应该类型的指针,即一个指向该类型的初值的内存地址的指针
- make
只用于channel,map,slice三种的内存创建,返回的类型就是这三个类型本身,只不过是初始化过的,因为这三种类型就是引用类型,所以就没有必要返回他们的指针了。
好了,前面只是简单复习一下,这里主要要了解new和make的分配位置,是堆还是栈?
逃逸规则
最普遍的规则:如果变量需要使用堆空间,那么他就应该进行逃逸
但还有很多种情况,一般我们给一个引用类对象中的引用类成员进行赋值,可能会出现逃逸现象,可以理解为访问一个引用对象实际上底层就是通过一个指针来间接的访问,那么再访问里面的引用成员就会有第二次间接访问,这样操作这部分对象的话,极大可能会出现逃逸的现象。
引用类型:func,interface,slice,map,channel,*
其实我的理解就是两引用的类型,对该值赋值,则一定发生逃逸
如果函数外部没有引用,则优先放到栈中,如果函数外部存在引用,则必定放到堆中,其实也不一定是函数,就是取决于引用的外部有没有在引用
所以go中,new和make的值分配到哪里,是说不准的,是由编译器决定的,先做逃逸分析,再决定分配到哪里~
Golang的gc机制(重点~)
垃圾回收(Garbage Collection,简称GC)是编程语言中提供的自动的内存管理机制,自动释放不需要的内存对象,让出存储器资源。
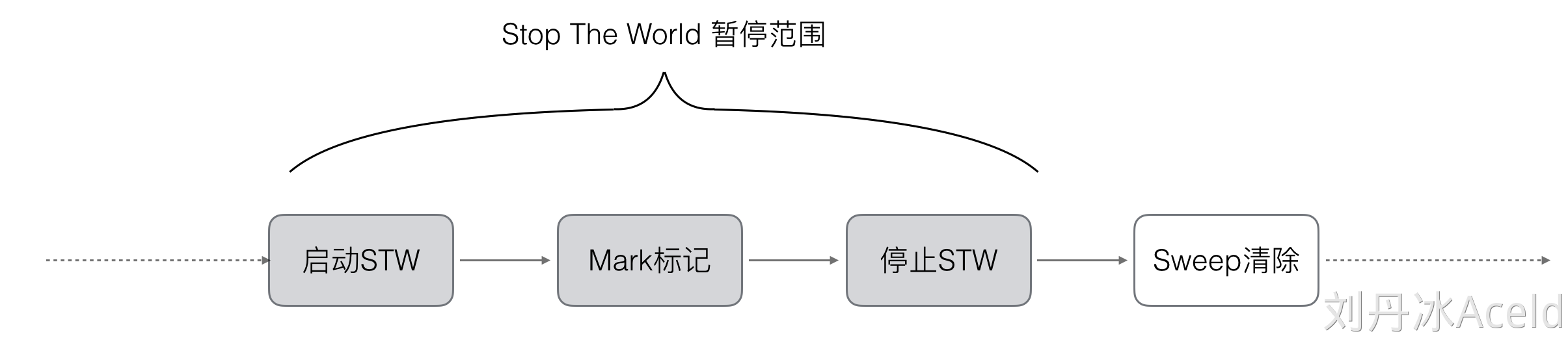
标记-清除(mark and sweep)
顾名思义,分为两步
- 标记(Mark phase)
第一步STW(暂停程序业务逻辑),分类出可达和不可达的对象,然后做上标记
相关信息
这里要知道一个概念,叫根集,即全局变量、函数栈、寄存器等,指的是程序运行中一直存在,不能被回收的对象集合,它们引用了其它对象,从根集出发遍历对象图,可以找到所有的可达对象。根集一般是在栈上,以及全局变量区和寄存器中。根集包括的都是运行过程中不会改变的。
可达和不可达对象都是从根集开始,找到与之相连的对象为可达
- 清除(Sweep phase)
第二步,清除未标记的对象
其实GC最主要的问题就是STW(Stop the world),STW的过程中,CPU全部用于进行垃圾回收,影响很大,所以回收机制需要优化的就是STW这一步。
标记清除方法的优点就是简单,缺点也很多
- STW(重要问题)
- 标记需要扫描整个堆
- 清除数据会产生heap碎片
Go1.3做的优化就是将STW的结束提前,但是实际还是影响很大(原先停止STW是在最后一步)
三色并发标记法
这里是GC的重点,Go1.5以后采用了新的gc机制
- 第一步
每次创建新的对象,默认颜色都是白色,加入白色集合
- 第二步
每次GC回收开始,会从根节点开始遍历所有的对象,把遍历到的对象从白色集合放入灰色集合
这里只需要遍历一层,而不需要遍历到底
- 第三步
遍历灰色集合,将灰色对象引用的对象从白色集合放入灰色集合,之后将此灰色对象放入黑色集合。
- 第四步
重复第三步,直到灰色集合中没有对象
- 第五步
回收所有的白色集合的对象
四步完成以后,只剩下白色和黑色集合是有对象的,那么黑色对象就是我们程序逻辑可达的,是有用数据,白色的对象是全部不可达对象,目前程序逻辑并不依赖它们,那么需要被清除
这五步是很好理解的,但是我们还想要知道是如何解决GC回收中的STW机制呢
没有STW的三色标记
如果没有STW的话,垃圾回收会有什么影响?
其实就有点类似于并发会怎么样呢(垃圾回收和程序并发),我们知道,程序运行过程中,对象的引用关系是可能随时改变的,如果这些改变在标记阶段进行了修改,会发生什么呢?
- 特殊情况
如果初始状态设置为经历了第一轮扫描,目前黑色的对象有1和4,灰色有2和7,其他为白色,且对象2通过p指针指向对象3
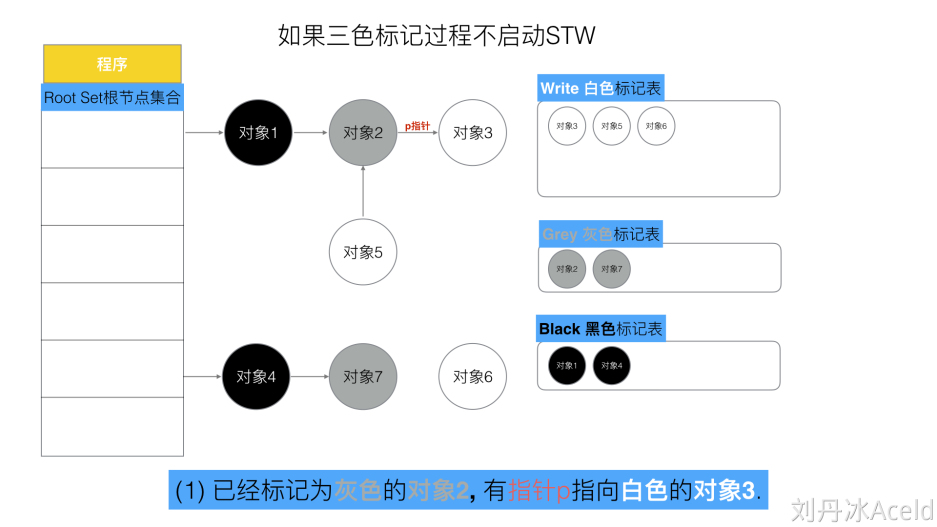
这时候,对象4通过指针q指向对象3,而对象2指向对象3的指针移除了,那么白色的对象三是挂在了扫描完成的黑色对象4下,但是在下一轮扫描的时候,黑色不会扫描了,而灰色对象2也指不到对象3,那就会出现一个问题,明明是可达对象的对象3,却被作为垃圾内存释放掉了
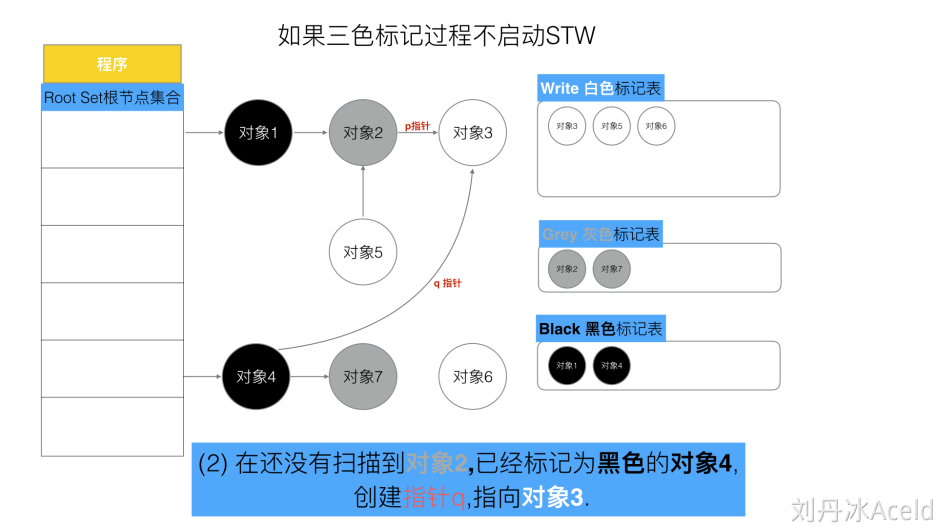
那可以看出,有两种情况,是三色标记法中不希望发生的
- 条件1:一个白色对象直接被黑色对象引用
- 条件2:灰色对象与它之间的可达关系的白色对象遭到破坏
如果同时满足两个条件,则会出现对象丢失,所以需要想办法破坏两个条件中至少一个。
为了防止这种现象,所以才有了STW,直接禁止了GC同时修改的对象引用关系的可能,但是STW有很明显的资源浪费,需要优化,所以需要在保证对象不丢失的情况下合理的尽可能的提高GC效率,减少STW时间的方法,即破坏上面两个必要条件之一
屏障机制
强-弱三色不变式
- 强三色不变式
不存在黑色对象引用到白色对象的指针,即黑色对象没法直接指向白色对象,破坏了条件一
- 弱三色不变式
所有黑色对象引用的白色对象都处于灰色保护状态
弱三色不变式强调,黑色对象可以引用白色对象,但是这个白色对象必须存在其他灰色对象对它的引用,即破坏了条件二
明白了两个概念,那就接着往下看
插入屏障
在A对象引用B对象时,B对象被标记为灰色。
满足了强三色不变式
相关信息
当然,插入屏障还需要知道一点,就是我们知道黑色对象要么在堆要么在栈种,栈空间的特点是容量小,但是速度快,因为函数调用弹出频繁使用,所以“插入屏障”机制在栈空间的对象操作中不适用,而仅仅使用在堆空间对象的操作中
换句话说,如果每次在栈中插入都要检查,会让栈的速度变慢,那就没有了栈的意义了,所以为了性能,不进行插入屏障,而是在最后再扫描一次。
而且在栈中实现插入屏幕也有一些技术难点,栈上的数据通常是按照一定规则进行压栈和出栈操作,当一个对象从栈上被弹出,如果需要进行垃圾回收,则需要查询堆内存中的对象,这个过程非常耗时。
这样的话正常一个流程下来,由于栈是没有插入屏障的,那么就可能会有白色对象被引用的情况,所以需要堆栈重新进行三色标记扫描,但为了对象不丢失,需要启动STW
删除屏障
被删除的对象,如果自身为灰色或者白色,那么被标记为灰色
满足了弱三色不变式
但是这种方法有缺陷,比如灰色对象一指向一个白色对象五,这时候把引用关系删除了,由于删除屏障,对象五变为了灰色,这时候五其实就是可达的了,但是实际上来说,对象五是不可达的,因为唯一的可达关系被删除了,但是由于删除屏障变成了灰色。
所以需要在下一轮GC才能将其删除,这种方式的回收精度较低。
Go1.8 混合写屏障(hybrid write barrier)机制
为什么需要新的机制,说明是前面的方法有着短板,先看看前两种屏障的短板
- 插入屏障:需要在最后对栈区域再进行一轮GC,此时要STW
- 删除屏障:精度低,可能会有不可达对象仍然存活,GC开始时需要进行STW
混合写屏障
- GC开始时将栈上的可达对象全部扫描并标记为黑色,之后就不需要再进行第二次扫描了,无需STW
- GC期间,任何在栈上新创建的对象,都是黑色
- 被删除的对象标记为灰色
- 被添加的对象标记为灰色
满足:变形的弱三色不变式
这里的屏障技术依然是不在栈上应用
Golang中的混合写屏障满足弱三色不变式,只需要开始时并发扫描各个goroutine的栈,使其变黑并一直保持,这个过程无需STW,而标记结束后,因为栈在扫描后还是黑的,也无需进行re-scan操作,减少STW时间。
问题
- 什么时候会触发GC
- 手动触发
runtime.GC
- 系统触发
系统触发有三种场景
- 对象数量达到一定阈值会启动GC
- 当距离上一个GC周期超过一定时间,会触发
- 内存空间不足,当前可用的内存空间不足满足正在运行的程序需求,GC会启动
- 内存分配速率:如果程序的内存分配速率超过了一定的阈值,GC会启动
- STW的时机
interface
interface是一种Duck Typing,即鸭子类型,这个词源自于"如果一个东西它走起路来像鸭子,叫起来也像鸭子,那么它就是鸭子"的说法
理解interface,需要明白几点
- interface是一个类型
- interface是方法声明的集合
- 任何类型的对象实现了在interface接口中声明的全部方法,则表明该类型实现了该接口
- 实现了该接口的任何对象都可以给对应接口类型变量赋值
- 方法不能重载,如
eat(),eat(s string)不能同时存在
面向对象(OOP)
继承、封装、多态,面向对象的三大特征,相信大家都有所了解
Golang不是面向对象语言,但是通过struct,interface和Method等机制,也能使用面向对象编程的思想
例如用interface和Method就可以实现出多态的效果
golangpackage main import "fmt" type Phone interface { call() } type NokiaPhone struct { } func (nokiaPhone NokiaPhone) call() { fmt.Println("I am Nokia, I can call you!") } type ApplePhone struct { } func (iPhone ApplePhone) call() { fmt.Println("I am Apple Phone, I can call you!") } func main() { var phone Phone phone = new(NokiaPhone) phone.call() phone = new(ApplePhone) phone.call() }
开闭原则
interface也是软件设计的一个方法,软件设计的最高目标是高内聚、低耦合
- 耦合
模块之间的依赖关系,当两个模块之间的依赖关系越强,它们之间的耦合就越紧密,耦合度高会增加代码的复杂性,以及维护难度和扩展难度
- 内聚
模块内部的功能联系,当一个模块内部的元素相互依赖,共同实现一个特定功能时,认为具有较高的内聚性,可以更加清晰地表达其功能和实现,实现细节更加易于理解和维护
什么是软件设计的开闭原则?
平铺式的模块设计
只构建一个结构体,然后疯狂添加该结构体对应的方法,这样每次修改都需要直接修改原有的代码,模块功能也会越来越大,就很容易出问题,因为这样很容易导致耦合度太高。
开闭原则设计
而使用interface建立一个抽象的模块,抽象一层出来,然后提供抽象的方法,分别根据这个抽象模块去实现各自不同的Branker模块
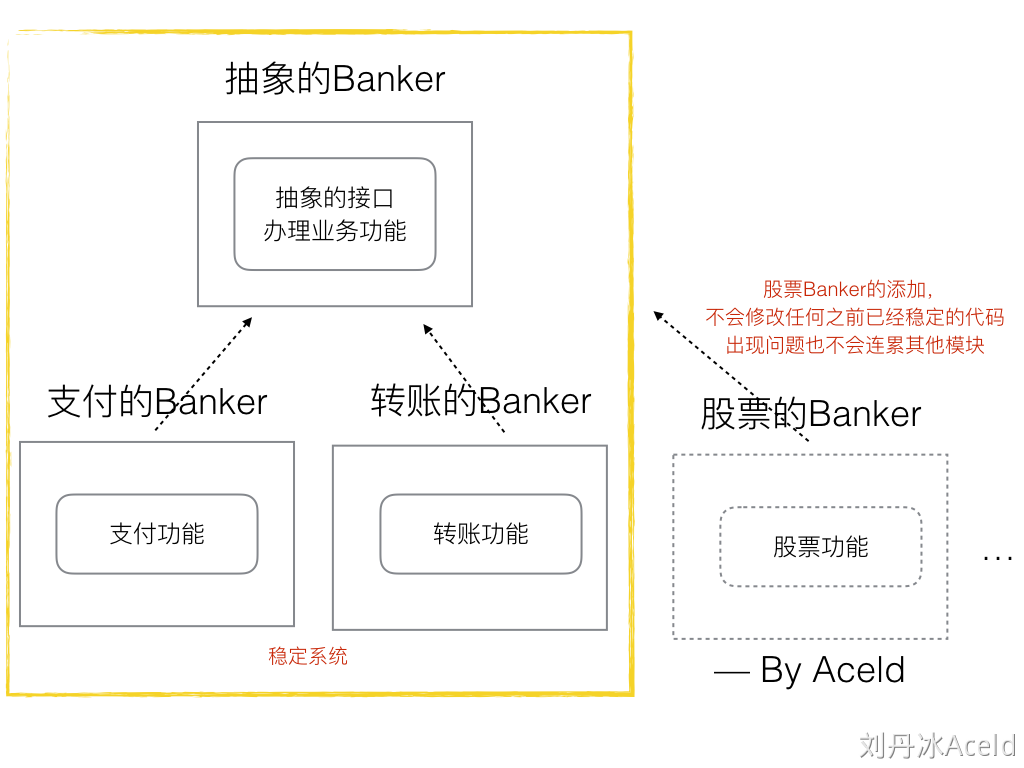
依赖倒转原则
channel
channel的作用是什么?
channel是一种用来在goroutine之间进行通信的机制
- goroutine之间传递数据,通过channel实现数据共享和交流
- 同步操作:在一个goroutine中发送数据到channel上,要等待另一个goroutine从channel中读取数据后才能往下继续,否则操作会阻塞
特性
- 给一个nil channel发送数据,会造成永远阻塞
- 给一个nil channel接收数据,造成永远阻塞
- 给一个已经关闭的 channel 发送数据,引起panic
- 从一个已关闭的 channel 接收数据,如果缓冲区中为空,则返回一个零值
- 无缓冲的 channel 是同步的,而有缓冲的 channel 是非同步的
除了以上以外,channel还是线程安全的
多个协程可以同时读写一个channel,而不会发生数据竞争的问题,这是因为Go语言中的channel内部实现了锁机制,保证了多个协程之间对channel的访问是安全的
使用场景
- 无缓冲
无缓冲区是同步的,又称为阻塞的通道,有一个读就需要有一个写,否则会死锁
golangfunc main(){ ch := make(chan int) ch <- 10 fmt.Println("发送成功") }
执行时会出现 fatal error : all goroutines are asleep - deadlock
所以需要创建一个协程去接收
- 有缓冲
golanga := make(chan int, 1)
- close
如果管道不存值或取值时记得关闭管道,而且可以通过close来控制关闭所有下游协程
-
单向管道
-
chan <- int 是只能发送的通道
-
<- chan int 是一个只能接收的通道
很多时候在不同的任务函数中使用通道会对其进行限制,比如限制通道在函数中只能发送或者接收
golangfunc counter(out chan<- int){ for i := 0;i < 100; i++{ out <- i } close(out) } func squarar(out chan<- int,in <-chan int){ for i:=range in { out <- i * i } close(out) } func printer(in <- chan int){ for i := range in{ fmt.Println(i) } } func main(){ ch1 := make(chan int) ch2 := make(chan int) go couter(ch1) go squarer(ch2,ch1) printer(ch2) }
- 操作加上超时
select + time.After,看操作和定时器哪个先返回,处理先完成的,就到达了超时控制的效果
golangselect { case ret := <-do(); return ret,nil case <- time.After(timeout); return 0,errors.New("timeout") }
设计
Golang的Channel设计理念是遵循CSP(通信顺序进程)的设计理念
CSP可以概括为以下三点:
- 独立执行:每个进程都是独立执行的,它们各自拥有自己的内部状态
- 通过通信协作:进程之间通过发送和接收消息来协调协作,这些消息可以包含一些带值的数据,也可以是简单的信号
- 没有共享状态:每个进程只能访问自己的上下文和内部状态
TODO:具体设计等待后续了解
Slice
defer的使用
defer是用于注册延迟调用的关键词
这些调用直到函数返回前才被执行,因此可以用来做资源清理
触发defer的有两个,一个是return,另外一个是panic,如果有panic则会使得defer出栈,若是有recover则停止panic,返回recover处继续往下执行,如果没有recover,遍历完defer后向stderr抛出panic信息。
- 执行顺序
defer是一个栈的关系,即先进后出,一个函数中,写在前面的defer会比写在后面的defer调用的晚
- defer,return的执行顺序
defer、return、返回值三者的执行顺序:
return 先执行,return负责将结果写入返回值中,接着defer开始执行一些收尾工作,最后函数携带当前返回值退出
- panic和defer
如果在defer里有另外一个panic,那么defer中的recover只会捕获最后一个panic
map
锁
Context
两个根函数
- context.Background()
- context.TODO()
四个with函数
- context.WithCancel:返回一个子ctx和cancel方法,调用cancel会发送给
ctx.Done() - context.WithTimeOut:即使超时会往ctx.Done()发送,但是也要自己调用
cancel() - context.WithDeadline:同上
- context.WithValue: 注意key要使用自定义类型
注意事项:
- 不要把Context放在结构体中,要以参数的方式显示传递
- 以Context作为参数的函数方法,应该把Context作为第一个参数
- 给一个函数方法传递Context时,不要传递nil,可以传
context.TODO() - Context的Value相关方法应该传递请求域的必要数据,不应该用于传递可选参数
- Context是线程安全的,可以放心的在多个goroutine中传递
Golang语言特性问题
struct的比较问题
- 只有相同类型的结构体能够比较,结构体是否相同不但与属性类型个数有关,还与属性顺序相关
- 结构体中的属性不能有不可比较的类型,如map,slice等
- 可以用reflect.DeepEqual进行比较
常量
golangpackage main const cl = 100 var bl = 123 func main() { println(&bl,bl) println(&cl,cl) }
该代码会报错,cannot take the address of cl
常量不同于变量的在运行期分配内存,常量通常会被编译器在预处理阶段直接展开,作为指令数据使用
内存四区的概念
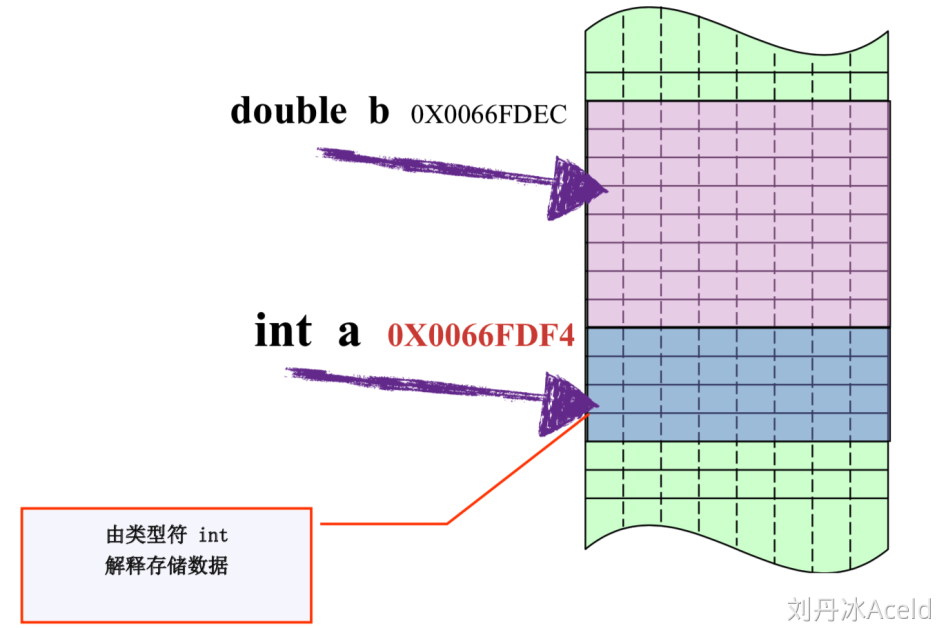
- 数据类型本质
数据类型的本质其实是声明这个数据内存大小的别名
- 数据类型的作用
编译器预算对象(变量)分配的内存空间大小
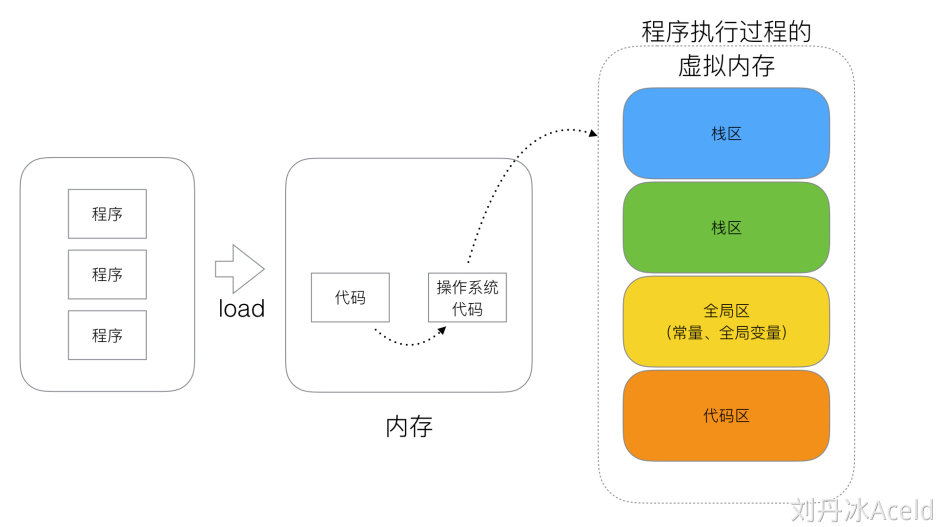
- 内存四区
程序执行时的虚拟内存分为四个区域:
- 栈区
- 堆区
- 全局区(常量,全局变量)
- 代码区
流程:
- 操作系统把物理硬盘的代码load到内存
- 操作系统把代码分成四个区
- 操作系统找到main函数入口执行
- 栈区
空间较小,要求数据读写性高,数据存放时间较短暂,由编译器来自动分配和释放,存放函数的参数值、函数的调用流程方法地址、局部变量等(局部变量可能由于发生内存逃逸而分配到堆区)
- 堆区(heap)
空间较大,数据存放时间较久,一般由开发者分配和释放(golang主要由编译器自己决定分配地址),会启动golang的gc由gc清楚机制自动回收
- 全局区-静态全局变量区
全局变量的开辟是在main执行之前就放在内存中了,而且对外完全可见(作用域是全部代码,桶包代码可随时使用。
全局变量会在进程退出时,由操作系统进行回收
- 全局区-常量区
常量为存放数值字面值单位,即不可修改,或者说有的常量是直接挂钩字面值的,在golang中,常量无法取出地址的,因为字面量符号没有地址而言。
不同包的多个init函数的运行时机
init和main函数的执行顺序
init函数在main函数开始前执行
如何删除切片中的某一个元素
sync.Map{}怎么使用
go的读写锁怎么工作
多个并发操作对map进行读写,程序会发生什么
超时处理
context.WithTimeout
子goroutine的panic会不会被父goroutine捕获
不会
Go函数中为什么会发生内存泄漏
明明go有gc机制了,为什么还会发生内存泄漏?
因为存在一种情况,比如goroutine需要维护执行用户代码的上下文信息,在运行过程中就需要消耗一定的内存来保存这类信息,如果一个程序持续不断地产生新的goroutine,且不结束已经创建的goroutine并复用这部分内存,就会造成内存泄漏的现象。
-
因为协程被永久阻塞而造成的永久性内存泄漏
一个程序中的某个协程会永久处于阻塞状态,go不会将处于永久阻塞状态的协程杀掉,所以永久阻塞状态的协程所占用的资源将永得不到释放。 -
因为没有停止不再使用的
time.Ticker值而造成的永久性内存泄漏
当一个time.Timer值不再被使用,一段时间内会被自动回收,而对于一个不再使用的time.Ticker,我们必须调用Stop方法结束,否则永远不会得到回收
因为行为略有不同,所以导致了在不使用时的回收行为上的差异
time.Timer是表示单次定时任务的类型,当创建一个time.Timer实例后,可以使用time.AfterFunc()或time.NewTimer()方法设置定时器,并在指定时间间隔后触发回调函数,就会被自动释放,并可以进行垃圾回收time.Ticker是一个表示重复定时任务的类型,会按照指定的时间间隔周期性地触发回调函数,与time.Timer不同,time.Ticker在不再使用时不会自动收回,会一值保持运行直到你调用Stop()方法显示停止,这是因为time.Ticker会保持内部的定时器资源,以便在每次触发后重新计时并保持周期性运行
内存泄漏了要如何检测
pprof或者Gops
Go中两个nil有可能不相等吗
有可能的,interface是对非接口值的封装,内部实现包含两个字段,类型T和值V,一个接口等于nil是当且仅当T和V处于unset状态(T=nil,V is unset)
unset就是变量处于默认的零值
两个接口值比较时,会先比较T,再比较V,接口值与非接口值比较时,会先将非接口值转换为接口值,再进行比较。
这样就很清楚了,看下面代码:
golangfunc main(){ var p *int = nil var i interface{} = p fmt.Println(i == p) // true fmt.Println(p == nil) // true fmt.Println(i == nil) // false }
首先将一个nil非接口值p赋值给接口i,此时i内部字段为(T=*int,V=nil),i与p比较,将p转换为接口后再比较,所以i==p,p 与 nil比较,直接比较值
但是 i 与 nil 比较,会将nil转换为接口(T=nil,V=nil),所以不相等了
性能优化
- slice预分配内存
尽可能使用make()初始化切片时提供容量信息
linux
如何去查询某一行的数据
grep "search_string" file_path
sed -n 'line_numberp' file_path
怎么汇总url,统计每个url
怎么查找进程
ps -ef
怎么查找有go语言的进程
pgrep -a -f go
Docker
k8s
Kubernetes是一个可移植的、可扩展的开源平台,使用声明式的配置并依据配置信息自动地执行容器化应用程序的管理,属于容器编排工具
功能
容器是一个比较好的打包运行应用程序的方式,在生产环境中,需要管理容器化应用程序,并且确保其不停机地连续运行,例如一个容器故障停机,另外一个容器需要立刻启动以替补停机的容器,类似这种对容器的管理动作由系统来执行会更好更快速
-
服务发现和负载均衡
Kubernetes可以通过DNS名称或IP地址暴露容器的访问方式,并且可以在同组容器内分发负载以实现负载均衡 -
存储编排
Kubernetes 可以自动挂载指定的存储系统,例如local storage/nfs/云存储等 -
自动发布和回滚
-
自愈
- 重启已经停机的容器
- 替换、kill那些不满足自定义健康检查条件的容器
- 在容器就绪之前,避免调用者发现该容器
- 密钥及配置管理
Kubernetes可以存储和管理敏感信息,可以更新容器应用程序的密钥、配置等信息,而无需重新构建容器的镜像,或在不合适的地方暴露密码信息
架构
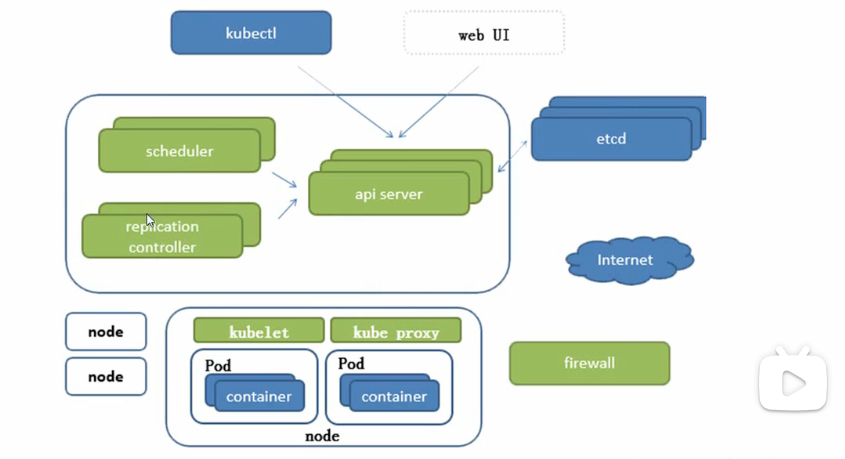
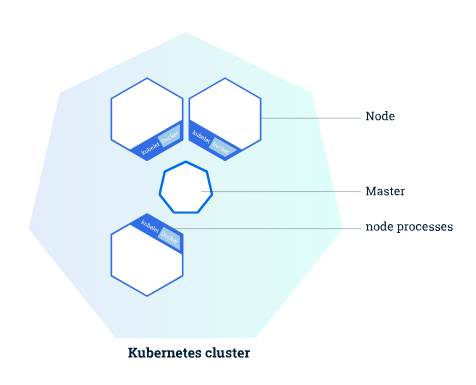
如上图,Master 负责管理集群,负责协调集群中的所有活动,例如调度应用程序,维护应用程序的状态,扩展和更新应用程序
Worker节点即图中的Node是VM或物理计算机,充当k8s集群中的工作计算机,每个Worker节点中都有一个Kubelet,管理该Worker节点并负责与Master节点通信,该Worker节点还应具有处理容器操作的工具,例如Docker
redis
数据类型
- SDS 简单动态字符串
字符串是redis中最常用的,由于C语言中字符串存在一定的问题,redis官方实现了自己的字符串结构来进行存储,其实就是在字节数组之上封装了一层
cstruct __attribute__ ((__packed__)) sdshdr8{ // 使用的长度 uint8_t len; // 分配的长度 uint8_t alloc; unsigned char flags; // 字节数组 char buf[] }
解决了几个问题
- 二进制安全
- 字符串可变
- 减少内存重分配次数
- O(1)获得长度
我们要知道,在C语言里,字符串是以\0分割的,所以在C语言中是有限制,但是redis需要的字符串存储是没有限制的,允许存入各种字符,所以增加了使用长度的内容,就无需再去理会分割处在哪里,只需要读出对应长度的数据就是要的内容。
而且redis更改了分配的策略,减少内存重分配次数,要知道内存分配是耗费资源的操作,因为涉及到了系统调用,redis实现了空间预分配和惰性空间释放两种优化策略
- 空间预分配
两种策略
- 当len<1MB时,那么会分配给新增后的字符串的len属性同样大小的未使用空间
- 当len>1MB时,会分配1MB未使用空间
- 惰性空间释放
用来优化SDS的字符串缩短操作,程序不立即使用内存重分配来回收缩短后多出来的字节,而是使用free属性将这些字节数量记录起来,并等待将来使用。
线程模型
持久化机制
主从复制原理
高可用
redis cluster
分布式锁
消息中间件
hash一致性算法
lua脚本
问题
关系型数据库和非关系型数据库的区别
- 结构化:每个表是有固定结构的,要预定义好对应的数据模型,而非关系型是非结构化的,没有任何预定义的数据模型
- 关系:关系型的表与表之间可能会有外键约束等关联起来,而非关系型则是互相独立的
- sql&Nosql:关系型数据库使用的sql语言,而非关系型各有各的调用方法
redis脑裂问题
mysql
Mysql架构
Mysql我们大部分人都经常用,那么一条执行语句的流程是怎么样的呢,中间发生了什么?
先了解一下整个Mysql的架构
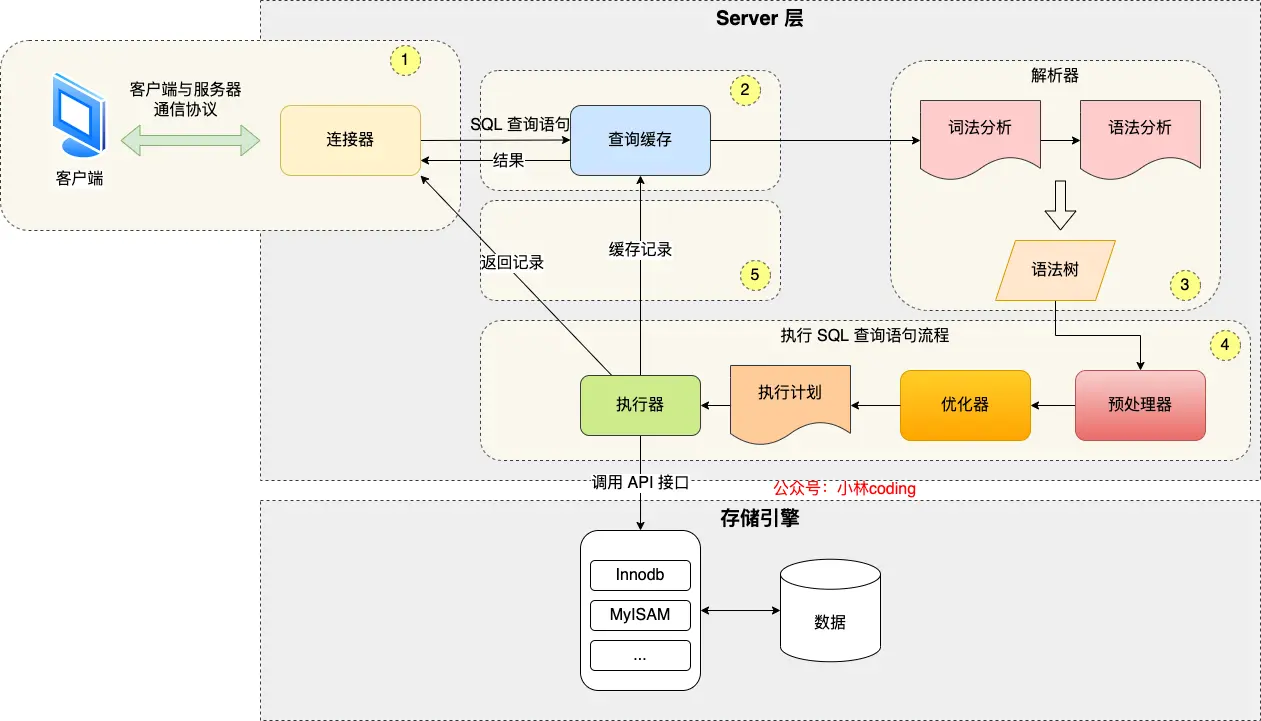
Mysql的架构如图,主要分成两层,Server层和存储引擎层
- Server层
Server层包含连接器,查询缓存,分析器,优化器,执行器等,涵盖Mysql的大多数核心服务功能,以及所有的内置函数,所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等
- 存储引擎层
负责数据的存储和提取,支持InnoDB、MyISAM、Memory等多个存储引擎.
连接器
Mysql的连接是基于TCP的,连接需要先经过TCP三次握手(mysql -uroot -p),如果TCP连接建立后,就需要验证身份(输入密码),成功后则获取该用户权限,然后基于开始时读取到的权限进行权限逻辑的判断(所以修改权限后需要重新连接)
查看Mysql服务端被多少客户端连接
show processlist
连接完成后,如果没后续动作就处于空闲状态,如果太长时间没动静则会被连接器自动断开,由参数wait_timeout控制的。
建立连接的过程是比较复杂的,所以要尽量减少建立连接的动作,即尽量使用长连接
但是如果使用长连接过多,可能会导致内存增长过快,因为有些资源是在连接断开时才会释放,所以长连接过多会导致内存占用太大,被系统强行杀掉,即Mysql异常重启。
解决方法
- 定期断开长连接,或者执行一个占用内存的大查询后,需要断开连接,之后需要再查询
- 版本大于>5.7 每执行一个比较大操作,执行mysql_reset_connection来重新初始化连接资源。
查询缓存
连接完之后就可以通过TCP来传递语句了,如果是select语句的话,就会来到第二步,查询缓存。
如果查询的语句命中查询缓存,那么就会返回value给客户端,如果查询语句没有名字查询缓存,那么就往下执行,等执行完毕后再将结果加入查询缓存。
但是实际上查询缓存并不怎么被使用,这是为什么?
我们知道在Mysql中,除了select外,还有其他三种基本语句,他们会更新了表中的数,那么原来对应表的查询缓存就失效了,所以很大可能查询缓存没被使用就又被清空了,除非业务是只有静态表,很久才更新,主要是读数据,才适合用查询缓存。
所以Mysql8.0版本删除了查询缓存,而在这个版本之前,则通过参数query_cache_type设置为DEMAND
分析器
我们知道sql是一门程序设计语言,那么还是为了方便自然语言理解而设计的,实际上还要转为机器语句来执行,那么自然需要有这一步来进行分析语言。
分析器首先需要做词法分析,输入的是多个字符串和空格组成的语句,这一步需要解析出每个字符串分别代表什么
下一步是语法分析,根据词法分析的结果,语句分析器根据语法规则,判断输入的SQL语句是否满足MYSQL语法。如果错误的话则会返回You have an error in your SQL syntax的错误提醒,这个错误在初学时应该是特别常见的。
相关信息
这里只是校验语法错误,而表或字段存不存在不是在这里判断的(这里与Mysql45讲中说的不同) 这一问题还得具体了解。
执行器
这里分成了三个阶段
- prepare 预处理阶段
- optimize 优化阶段
- execute 执行阶段
预处理阶段
这里做的就是前面说的,检查字段或表是否存在,
除此之外,还把*扩展为表上的所有列
优化器
接下来会为SQL查询制定一个执行计划,这个工作由优化器完成
比如多个索引时,选择哪个索引来执行,或者有多表关联语句时,决定各个表的连接顺序,比如
select * from t1 join t2 using(ID) where t1.c=10 and t2.d=20
既可以是从表t1里面取出c=10的记录的ID值,再根据ID值关联到t2,也可以是从t2里面取出d=20的记录的ID值,然后再根据ID值关联到t1
相关信息
想知道具体的执行计划,可以在查询语句前加explain命令,这样就会输出SQL语句的执行计划。
执行器
确定了前面的执行计划后,到这里才是真正的执行语句,在执行过程中,执行器和存储引擎交互,交互是以记录为单位的
首先会判断是否对该表有执行权限,如果没有则返回没有全错错误,如果有则打开表继续执行,执行器会根据表的引擎定义,去调用引擎提供的接口。
select * from T where ID=10
比如这个例子的表T中,ID字段没有索引,那么执行器的执行流程是这样:
- 调用InnoDB引擎接口取这个表的第一行,判断ID是否为10,如果不是则跳过,反之存到结果集中
- 调用引擎接口取下一行,重复第一步,知道取到最后一行
- 执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端
如果有所有的话,则是第一次调用的是取满足条件的第一行这个接口,接下来是调用满足条件的下一行接口,这些接口都是存储引擎提供的。
在数据库的慢查询日志中看到一个rows_examined字段,表示这个语句执行过程中扫描了多少行,这个值就是在执行器每次调用引擎获取数据行的时候累加的。
修改语句是怎么执行的
前面讲的是一条select语句的执行流程,更新语句其实大部分流程也是一样的,不过还涉及即个重要的日志模块
undo log
回滚日志,是Innodb存储引擎层生成的日志,实现了事务中的原子性,主要用于事务回滚和MVVC
我们在执行一条语句时,如果没有输入begin和commit来提交事务,一般会隐式开启事务来执行对应的语句,即执行完一句就会自动提交事务,可以在执行完语句后可以在数据库中及时看到结果。
但是如果是一个多语句的完整事务,那么如何在没提交前做回滚呢?
那么就是在每次事务执行过程中,记录下回滚时需要的信息到一个日志里,那么在事务执行中途发生了Mysql崩溃后,也不用担心无法回滚,我们可以通过这个日志回滚到事务之前的数据,这个机制就是undo log,保证了事务的原子性。
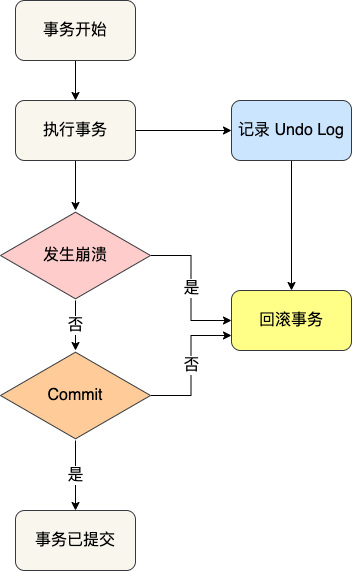
需要做的就是:
- 插入记录时,把记录的主键值记录下来,这样之后回滚时只需要根据主键取删除
- 删除记录时,把记录所有内容记录下来,之后重新插入回表中
- 更新记录时,记录旧值,然后重新更新回旧值即可
一条记录的每一次更新操作产生的 undo log格式都有一个roll_pointer指针和一个trx_id事务id
- 通过 trx_id 可以知道该记录是哪个事务修改的
- 通过 roll_pointer 指针可以将这些 undo log 串成一个链表,这个链表称为版本链。
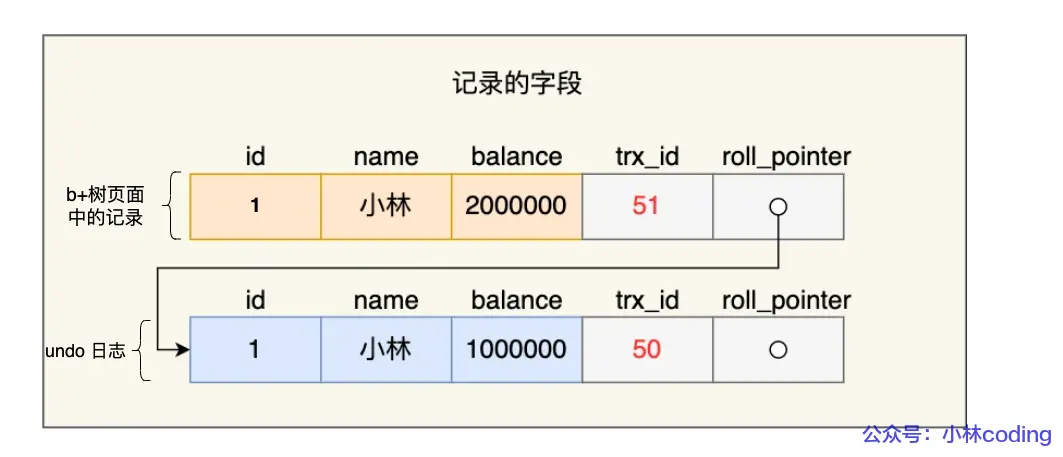
undo log + ReadView实现MVCC(多版本控制)
buffer pool
Mysql的数据都是存储在磁盘中,当需要更新一条记录时,得先从磁盘读取该记录,然后在内存中修改这条记录。如果每次都要从磁盘中读取就会很耗时间,所以这时候就考虑能不能做一个缓存来解决这个问题。
因此,Innodb设计了一个缓冲池(Buffer Pool),来提高数据库的读写性能
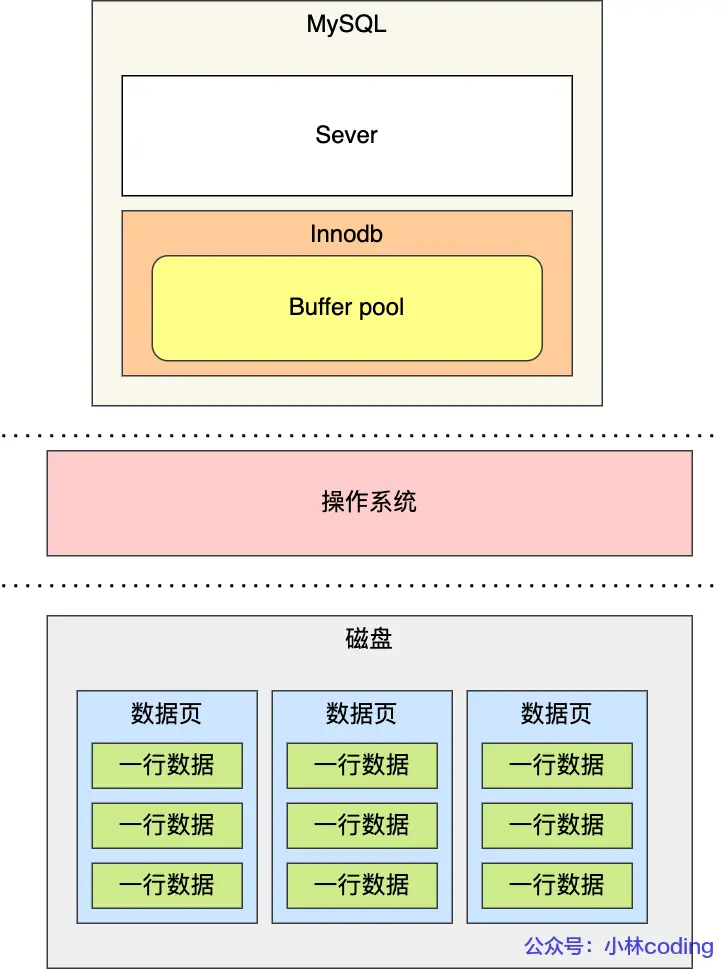
有了 Buffer Pool后:
- 当读取数据时,如果数据存在 Buffer Pool中,客户端就会直接读取 Buffer Pool中数据,否则再去读取磁盘
- 当修改数据时,如果数据存在,那么直接修改 Buffer Pool 中数据所在的页,然后将其页设置为脏页(即该页数据和磁盘上数据不一致),为了减少磁盘I/O,不会立即将脏页写入磁盘,后续由后台线程选择一个合适的时机将脏页写入到磁盘。
Innodb会把存储数据划分为多个[页],以页作为磁盘和内存交换的基本单位,一个页的默认大小为 16KB,因此,Buffer Pool 也需要按 [页] 来划分
redo log
重做日志,是Innodb存储引擎层生成的日志,实现了事务中的持久性,主要用于断电等故障恢复
binlog
归档日志,主要用于数据备份和主从复制
存储引擎
常见的存储引擎 InnoDB,MyISAM,Memory,NDB
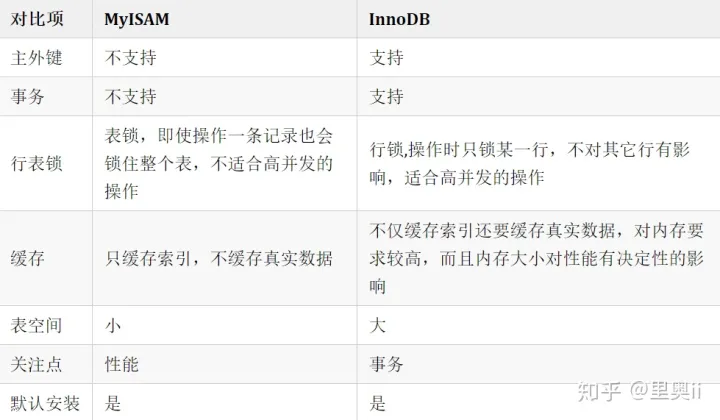
区别:
- InnoDB支持事务,MyISAM不支持事务,这是使用InnoDB作为默认存储引擎的重要原因
- InnoDB支持外键,而MyISAM不支持,对一个包含外键的InnoDB表转为MyISAM会失败
- InnoDB是聚簇索引,而MyISAM是非聚簇,聚簇索引的文件存放在主键索引的叶子节点,因此InnoDB必须要有主键,通过主键索引效率高,而辅助索引需要查两次,先查询到主键再通过主键查数据,因此主键不应该过大,因为主键过大其他索引也会很大,而MyISAM是非聚簇索引,数据文件分离,索引保存的是数据文件的指针,主键索引和赋值索引是独立的。
- InnoDB不保存表的具体行数,执行select count(*) 需要全表扫描,而MyISAM用一个变量保存了整个表的行数,执行上述语句只需要读出该变量即可(这是由于InnoDB事务特性有关,由于MVCC的原因,InnoDB表应返回多少行是不确定的)
- InnoDB最小的锁粒度是行锁,MySIAM最小锁粒度是表锁,一个更新语句会锁柱整张表,导致其他查询和更新都会阻塞,因此并发访问受限制
索引
- 数据结构角度
- B+树索引
- Hash索引
- Full-Text全文索引
- R-Tree索引
- 物理存储角度
- 聚簇索引
- 非聚簇索引(辅助索引)
- 逻辑角度
- 主键索引
- 普通索引或单列索引
- 多列索引(复合索引、联合索引)
- 唯一索引或者非唯一索引
- 空间索引:对空间数据类型的字段建立的索引,空间类型分别有
GEOMETRY,POINT,LINESTRING,POLYGON,这个是只存在MYSIAM引擎的表中的
事务
锁
内存
集群
分库分表
首先我认为我们的原则就是:能不拆就不拆,能少拆就不多拆,因为维护起来是一件比较麻烦的事情。
- 分库:数据拆分到不同的Mysql库中
- 分表:把数据拆分到同一个库的多张表中
一般采用这种策略是为了解决两种问题
- 数据量太大查询慢的问题
一般是指事务中的查询和更新操作,因为只读的查询可用通过缓存和主从分离来解决,解决查询慢,只需要减少每次查询的数据总量就可以了,即分表可以解决问题
- 高并发的情况
基本是因为一个数据库实例支撑不住,所以将请求分散到多个实例中去,所以分库是解决这个问题的方法。
拆分顺序应该是先垂直再水平
- 垂直拆分
- 垂直分表
大表拆小表,基于列字段进行的拆分,一般是表中字段较多,将不常用的,数据较大,长度较长(比如text类型字段)的拆分到扩展表,也避免查询时,数据量太大造成的跨页问题
- 垂直分库
对系统的不同业务进行拆分,比如user一个库,Product一个库,订单一个库等,并且需要将切分的数据库放在多个服务器上,其实就和微服务的想法是一样的。
在高并发场景下,垂直分库一定程度上能突破IO、连接数及单机硬件资源的瓶颈
- 水平拆分
- 水平分表
针对数据量较大的单张表,按照某种规则(Range,Hash取模等),切分到多张表里面去,但是这些表还在同一个库中,所以库级别的数据库操作还是有IO瓶颈
- 水平分库分表
将单张表的数据切分到多个服务器上,每个服务器具有相应的库与表,只是表中数据集合不同。
-
水平分库分表切分规则
-
RANGE
从0-10000一个表,10001-20000另外一个表 -
Hash取模
将用户,订单作为主表,然后将和它们相关的作为附表,这样不会造成跨库事务之类的问题,取用户id,然后hash取模,分配到不同的数据库
-
地理区域
-
时间 - 冷热数据分离
-
不过分库分表的重点其实是拆分后面临的问题的解决方法:
- 事务支持
- 多库结果集合并
- 跨库join
性能优化
主从模式
主从模式一般就是读写分离,主服务器负责写数据,从数据库负责读数据,并保证服务器的数据及时同步到从服务器
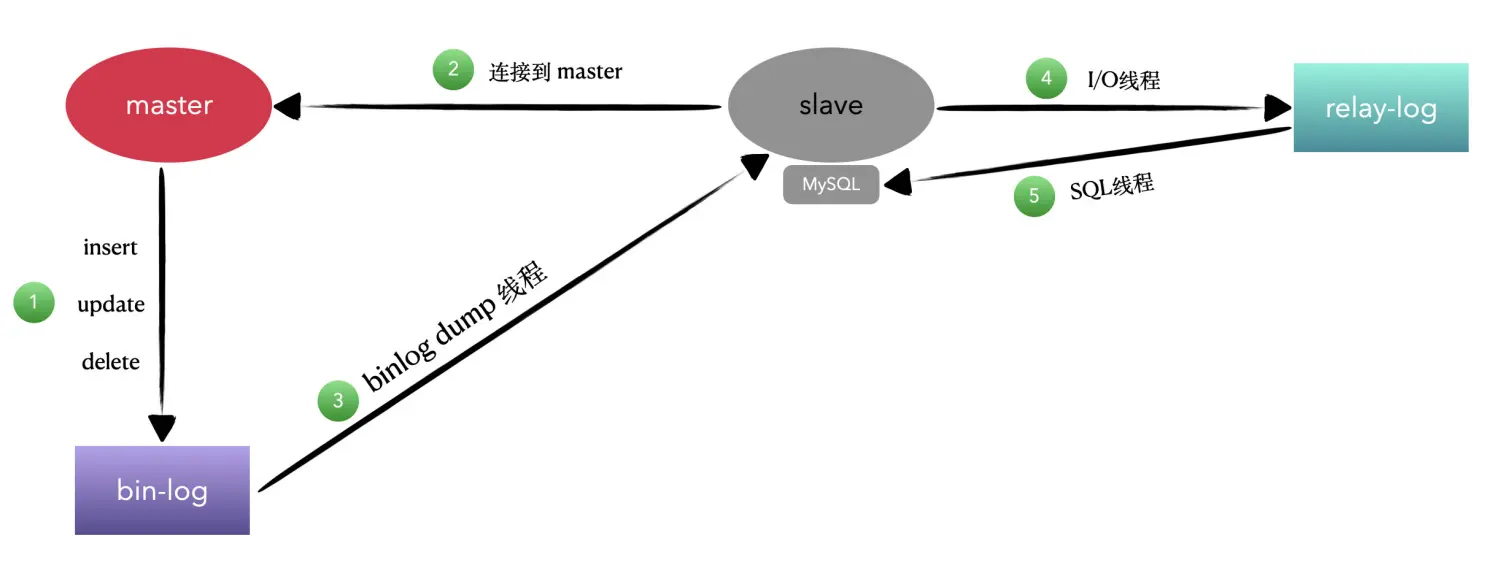
从图中可以看出,主服务器的读写会记录到bin log中,而slave服务器会专门起一个IO线程,去读主服务器的bin log,然后同步到自身的Relay Log文件中,同时mysql再起一个SQL线程,去读取Relay Log,将操作重放一遍
- 主库将数据库中数据变化写入到binlog
- 从库连接主库
- 从库创建一个I/O线程向主库请求更新的binlog
- 主库会创建一个binlog dump线程来发送binlog,从库中的I/O线程负责接收
- 从库的I/O线程将接收的binlog写入到relay log中
- 从库的SQL线程读取relay log 同步数据到本地,即再执行一遍对应SQL
- 主节点(master)
- 当主节点上进行insert、update、delete操作时,会按照时间先后顺序写入到binlog中
- 当从节点连接到主节点后,主节点会创建一个叫做binlog dump的线程
- 一个主节点有多少个从节点,就会创建多少个binlog dump线程
- 当主节点的binlog发生变化的时候,即进行了更改操作,binlog dump线程就会通知从节点(Push模式),并将相应的binlog内容发送给从节点
- 从节点(Slave)
当开启主从同步时,从节点会创建两个线程用来完成同步任务
- I/O线程:此线程连接到主节点,主节点上的binlog dump线程会将binlog的内容发送给此线程,此线程接收到binlog后,再将内容写入到本地的relay log
- SQL线程:该线程读取I/O线程写入的relay log,并且根据relay log的内容对从数据库做对应的操作
理论上怎么实现从库和主库的数据一致性?
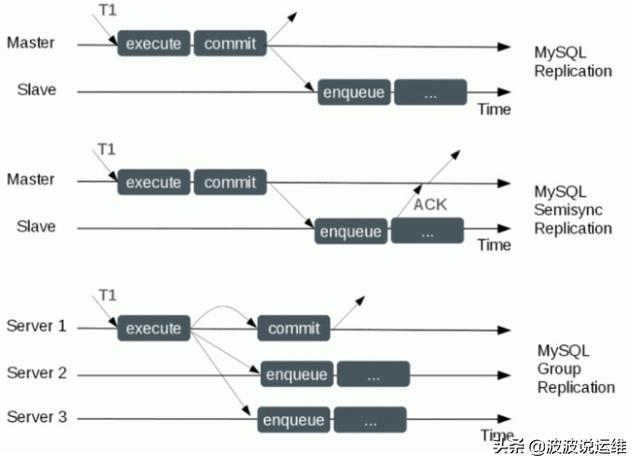
- 异步复制
主库在执行完客户端提交的事务会立即将结果返回给客户端,并不关心从库是否已经接收并处理,这样就存在一个问题,如何主库crash掉了,此时已提交的事务可能没有传到从库上,如果将从库提升为主库,会导致数据不一致的情况,但Mysql早期(5.5以前)只支持异步复制
- 半同步复制
主库在应答客户端提交的事务前需要保证至少有一个从库接收到了并且写到relay log中,半同步复制通过rpl_semi_sync_master_wait_point参数来控制master在哪个环节接收slave ack,master接收到ack后返回状态给客户端,此参数一共有两个选项AFTER_SYNC&AFTER_COMMIT
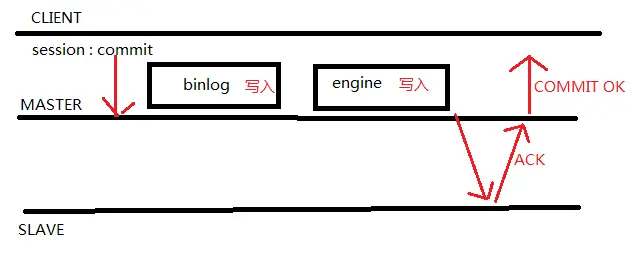
主库只需要等待至少一个从库节点收到并且 Flush Binlog 到 Relay Log文件即可,主库不需要等待所有从库给主库反馈,同时这里只需要一个收到的反馈,而不是已经完全并且提交的反馈,所以节省了很多时间,相对异步复制,提高了数据的安全性,但是造成了至少一个TCP/IP往返的时间
原理就是master将每个事务写入binlog(sync_binlog=1),传递到slave刷新到磁盘(sync_relay=1),同时主库提交事务(commit),master等待slave反馈收到relay log,只有收到ACK后master才将commit ok结果反馈给客户端
但也存在一种情况,我们知道,在等待Slave ack的时候,事务已经提交了,只是没有返回结果给客户端,所以其他客户端是会读取到已提交事务的,如果Slave端还没有读到该事务的events,同时主库发生了crash,然后切换到备库,就会出现数据不一致的问题,如果主库永远启动不了,那么实际上在主库已经成功提交的事务,在从库上是找不到的,这个情况有一个原因是因为从数据库从主数据库中获取binlog是分批次获取的,所以在未完全执行完后主库崩溃了会出现这种情况。
而且在半同步复制架构中,主库在等待备库ACK时,如果超时会退化未异步,也会导致数据不一致(rpc_semi_sync_master_timeout,默认未10s)
- 全同步复制
指当主库执行完一个事务,所有的从库都执行了该事务才返回给客户端,因为需要等待所有从库执行完该事务才能返回,所以全同步复制的性能必然会受到严重的影响,因为一个事务的完成时间被拉长了
但这个也不保证一定是数据一致的,因为当主库在binlog flush并且同步到从库之后,binlog sync之前发生了abort,那么很明显这个事务在主库是未提交成功的,但是从库已经收到了,所以会出现主从上的数据不一致。
常见问题
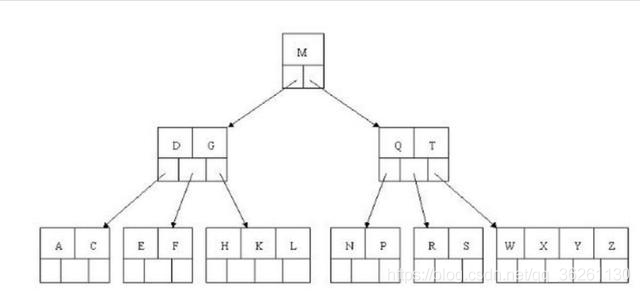
- 为什么索引使用B+树,和B树的区别
B树
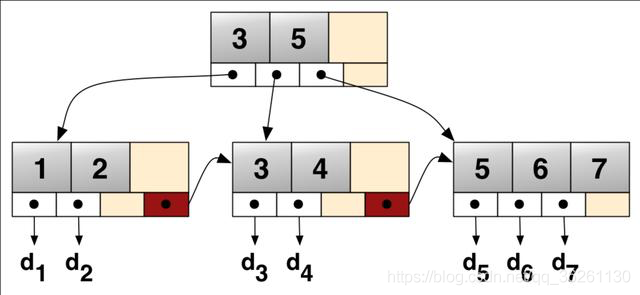
B+树
区别:
- B树的节点中没有重复元素,而B+树有
- B树的中间节点会存储数据指针信息,而B+树的数据只会存储在叶子节点
- B+树的每个叶子节点有一个指针指向下一个节点,把所有的叶子节点串在一起
选用B+树的原因:
- 查询速度快,因为中间节点不存储数据,所以同样大小的磁盘页可以容纳更多的节点元素,这样的话构造出来的树高度就更小,高度小则导致需要读取的磁盘页少,则读取次数少。
- B+树的所有数据都在叶子节点,所以在B+树中查找的时间更稳定
- B+树的每一个叶子节点都有指向下一个叶子节点的指针,方便范围查询和全表查询,而如果是B树的话还需要进行中序遍历。
mongodb
文档类型的数据库
elasticsearch
elasticsearch用于海量数据的搜索,基于全文搜索方面很有优势,是面向文档存储的
倒排索引
倒排索引是es的核心,像平常数据库是正向索引,即例如ID作为索引,那么如果根据id去查询的话就会很方便,但是如果我们是查找一个字符串字段,比如用like去匹配,那只能一行一行匹配,这样就会很耗时。
倒排索引在存储时,会分词,然后分为文档和词条,有点类似构造一个表,两个字段,词条和文档ID,词条是将字符串字段按一定规则进行分词的字符,而文档id是该词条在原先表中的ID,且词条不会重复,文档id可以多个,这样词条不重复就可以建立索引了。
- 文档:每条数据就是一个文档
- 词条:文档按照语义分成的词语
与Mysql对比
es是面向文档存储,而且文档数据会被转为json格式存储起来的
概念对比:
Mysql Elasticsearch 说明
Table Index 索引,即文档集合,同类的文档属于一个Index
Row Document 一个Json
Column Field JSON文档中的字段
Schema Mapping 索引中文档的约束,类似表结构(Schema)
SQL DSL
分词
官方提供的是适合英文分词,所以还是需要去下载ik插件,提供两种模式
- ik_smart 智能切分,粗粒度
- ik_max_word:最细切分,细粒度
那分词的原理是什么?如何去拆分,其实正常就是底层包括一个字典,字典中存在的词可以划分为一个词,但是存在一些问题,例如的字,字典存在这个词,但是有时单独分出来没有意义,或者一些不存在于字典中的词,但是又有必要的话该如何处理?
官方也有考虑这些问题,所以IK分词器其实是支持扩展词库的,需要修改一个ik分词器目录中的config目录下的IkAnalyzer.cfg.xml文件
ELK
ELK是一套针对日志做解决方案的框架,分别代表三个产品:
- E
(ES),负责日志的存储和检索 - L
负责日志的收集,过滤和格式化 - K
负责日志的展示统计和数据可视化
我们首先要了解它能为我们解决什么问题:
- 应用出现故障,需要通过日志排查故障信息,当应用已经部署了多个环境,这时排查的难度和耗时就会很大,而ELK则可以对多个环境的日志进行收集,过滤,存储,检错,可视化。到时只需要看Kibana上的日志信息就可以找到故障所在
- 针对应用在生产环境上的表现需要数据支撑,如访客数,功能调用量,出错率等。
日志是记录一个服务的所有行为的数据,而ELK则对服务行为数据进行分析。
消息队列
什么是消息队列,首先对列我们是很了解的,先进先出的一个数据结构,消息队列也是类似,就是把消息放到队列中
两个最常见的概念
- 生产者: 把数据放到消息队列叫做生产者
- 消费者: 从消息队列中取出数据
为什么要使用消息队列?
- 解耦
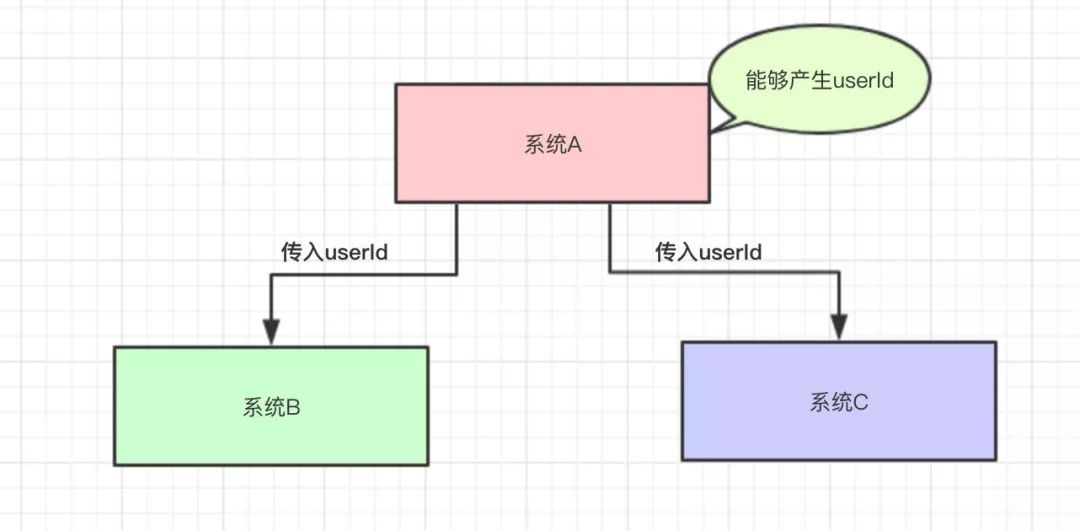
比如系统A能产生一个userid,而系统B和C都需要这个,就需要系统A去调用BC的方法传参,那么每次BC系统需要修改,比如不需要这个接口了,那是不是就需要不断的去改动系统A的代码,这样对系统A的维护者是一件很麻烦的事情,而且A去调用其他系统的话,那么调用过程中出现了问题又要怎么处理?又是一件麻烦事,那么使用消息队列就能解决这个问题
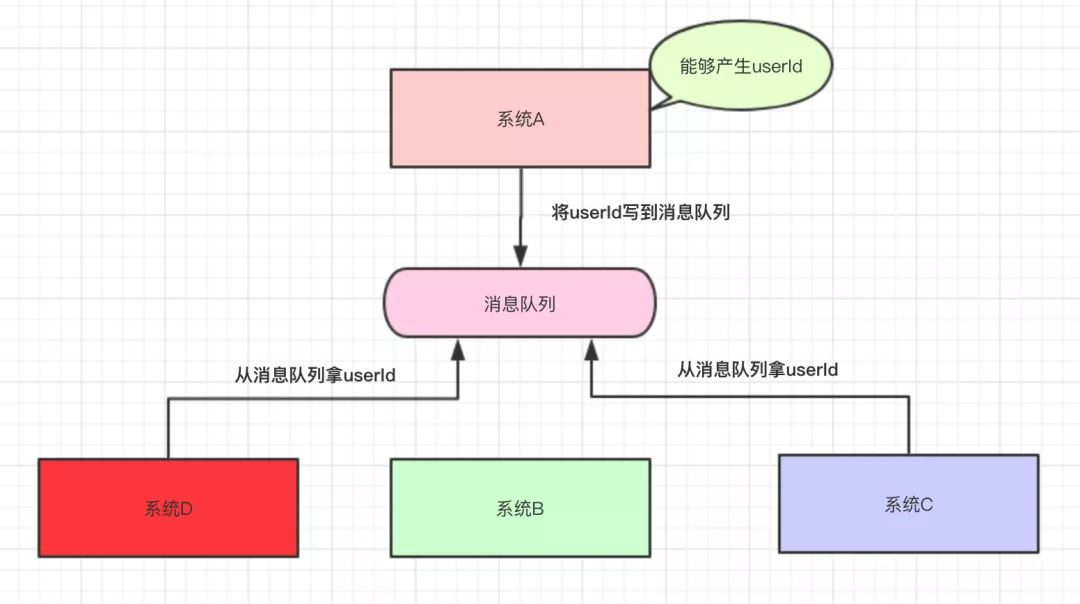
使用消息队列的好处:
- 系统A只需要将数据写入队列,使用者与系统A没有关系
- 新系统只需要从消息队列中拿,这样新系统无论宕机还是超时都与系统A没有关系
很明显,接下来其他系统的修改对于系统A没有多大影响了,这样系统A和其他几个系统解耦了
- 异步
这个就比较好理解了,主要是为了提高用户体验和吞吐量,比如一个注册系统,正常流程可能是注册完了,数据进入数据库中,再去执行发送短信或邮件功能通知用户,这个发送短信或邮件就会使得用户需要额外等待几秒才能获得注册成功提醒,那这时候就可以利用消息队列进行异步操作,在正常注册数据进入数据库后就将消息写入消息队列中,然后直接返回注册成功提醒,而另外一边的邮件/短信注册再从消息队列中读取消息,提供对应的发送功能
好处:
- 原先可以需要500ms才能返回(注册100ms+邮件400ms),现在只需要100ms即可
相关信息
当然这样也有问题,就是我们会想,这样做只是假装注册成功了,实际上邮箱验证之类或者后续的功能还没执行完,万一没执行成功岂不是注册失败了,这个就是消息队列要解决的问题了之一了-数据丢失问题。
- 削峰/限流
秒杀是最经典的场景,并发量较高,比如每秒5000个请求,而我们现在的两台机器支持不了这么大的请求量,那么就很容易系统崩溃,所以我们引入了消息队列,我们先将请求放入消息队列中,然后系统根据自己能够处理的请求数去消息队列中拿数据,这样即使每秒有10000个请求也不会使得系统轻易崩溃
相关信息
不过这样也有另外一个,就是我们需要保证消息队列中存储是有序的,否则后来的请求却在前面先被消费了,那么就有可能对先发送请求的人不公平,尤其在秒杀情况下,会使得先购买的人却买不到物品。
高可用
消息队列在系统中处于一个比较重要的地位,所以我们要保证其的高可用,不可能是单机处理的,不然一旦机器宕机,整个系统就不可用了,所以是采用集群/分布式的,那么就系统消息队列能提供现成的支持。
数据丢失问题
Redis中的数据就是持久化到磁盘中,那么消息队列也需要有一定的持久化策略,以避免数据丢失
消费者如何获得数据
- Push
生产者放入消息,消息队列主动叫消费者获取(Push) - 轮询
消费者不断去轮询消息队列,一旦有新消息才去消费(Pull)
其他
- 消息重复消费怎么处理
- 消息有序如何保证
这些在不同的消息队列中有着对应的解决方法,这里主要学习的是Rabbitmq和Kafka
通信模型
- 点对点模式
生产者发送消息到queue中,消费者从中取出并且消费,一条消息被消费后,queue就没有了,不存在重复消费
- 发布订阅模式
消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息,和点对点不同,发布到topic的消息会被所有订阅者消费
发布订阅模式下,当发布者消息量很大时,单个订阅者的处理能力是不足的,实际上现实场景是多个订阅者节点组成一个订阅组,负载均衡消费topic消息即分组订阅,这样订阅者很容易实现消费能力线性扩展,可以看成是一个topic下有多个Queue,每个Queue是点对点的方式,queue之间是发布订阅模式。
Zookeeper
Zookeeper是一个分布式应用程序的分布式开源协调服务,主要用来解决分布式应用中经常遇到的一些数据管理问题。
Kafka
Kafka是一种分布式的,基于发布/订阅的消息系统,主要设计目标如下:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级别以上数据也能保证常数时间复杂度的服务性能
- 高吞吐率(即单位时间处理的请求数),即使在廉价的商用机器上也能做到单机支持每秒100K条以上消息的传输
- 支持Kafka Server间的消息分区,及分布式消费,同时保持每个Partition内的消息顺序传输
- 同时支持离线数据处理和实时数据处理
- Scale out:支持在线水平扩展
特点是:高吞吐,低延迟.高容错
Kafka的一些概念
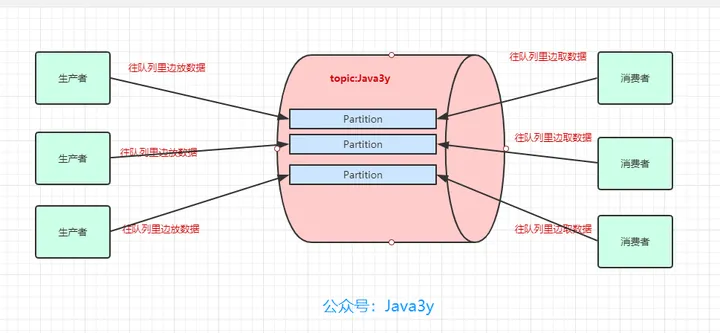
首先是两个概念,生产者和消费者,把消息放到队列里边的叫做生产者,从队列里消费的是消费者
而一个消息中间件,队列往往不单单只有一个,可能需要多个队列,而生产者和消费者需要知道把数据放入哪个队列,所以需要给每个队列有一个标识,叫做topic,相当于数据库中表的概念,一般是一个业务线建一个topic
之后为了提高一个队列(topic)的吞吐量,Kafka会把topic进行分区(Partition),所以实际上,生产者和消费者是从分区读写数据的
Broker则是一台Kafka服务器,集群则是多台Kafka服务器,一个topic会分成多个partition,而实际上partition会分布在不同的broker中
副本是Kafka中消息的备份(Replica)
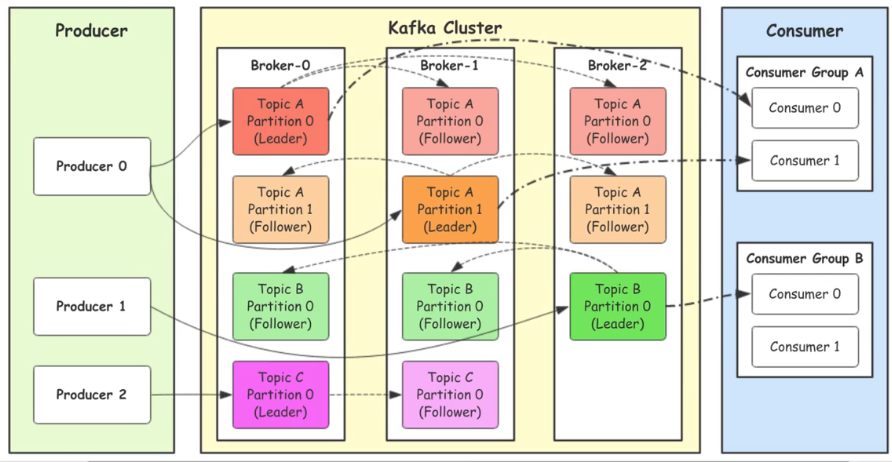
从图中也可以看到,一个Topic的同个分区。分为了Leader和Follower,生产者生产消息就是连接Leader,然后再由Leader去同步到follower中去,消费者也是从Leader中去消费消息,当主分区故障时会选择一个follower成为leader,follower和leader不能在同一个机器,同一个机器对同一个分区也只能存放一个副本
而分区(partition)的作用主要是为了负载,提高kafka的吞吐量,同一个topic在不同的分区的数据是不重复的,partition的表现形式就是一个一个的文件夹。
发送消息的步骤
- 生产者从Kafka集群中获取分区leader信息
- 生产者将消息发送给leader
- leader将消息写入本地磁盘
- follower从leader拉取消息数据
- follower将消息写入本地磁盘后向leader发送ACK
- leader收到所有的follower的ACK后向生产者发送ACK
选择partition的原则
在kafka中,如果某个topic中有多个partition,要怎么选择分区发送数据:
- partition在写入的时候可以指定需要写入的partition,如果有指定,则写入对应的partition
- 如果没有指定,但是设置了数据的key,则会根据key的值hash出一个partition
- 如果前面两者都没有,则会采用轮询方式,即每次取一小段时间的数据写入某个partition,下一小段的时间写入下一个partition
ACK应答机制
producer在向kafka写入消息时,可以设置参数来确实是否确认kafka接收到数据,这个参数值可以设置为0,1,all
- 0代表producer往集群发送数据不需要等待集群的返回,不确保消息发送成功,安全性最低但效率最高
- 1则是只有leader应答就可以发送下一条
- all代表需要leader和所有的follower都完成从leader的同步才会发送下一条,确保leader发送成功和所有的副本都完成备份,安全性最高,效率最低
Topic和数据日志
topic是同一类别的消息记录(record)的集合,kafka中,一个主题通常有多个订阅者,对于每个主题,kafka集群维护了一个分区数据日志文件,结构如下:
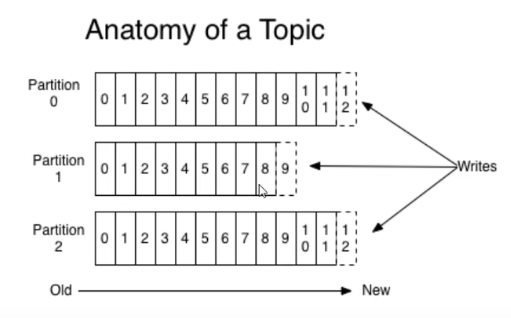
每个分区都是一个有序并且不可变的消息记录集合,当新的数据写入时,就被追加到分区的末尾,在每个分区中,每条消息都会被分配一个顺序的唯一标识,这个标识称为offset偏移量
注意
Kafka只能保证一个partition内部消息是有序的,在不同partition之间并不能保证消息顺序。
Kafka可以配置一个保留期限,用来标识日志在Kafka集群内保留多长时间,Kafka集群会保留在保留期限内所有未被发布的消息,不管这些消息是否有被消费过,超过了期限则会清空这些数据,以便为后续的数据腾出空间,由于Kafka会将数据进行持久化存储,所以保留的数据大小可以设置为一个较大的值
每个partition文件夹里有多组segment文件,每组segement文件又包含.index,.log,.timeindex三个文件,其中.log是实际存储message的地方,而另外两个文件为索引文件
消费数据
前面已经知道多个消费者可以组成一个消费者组,每个组有一个标签来唯一标识,如果所有的消费者实例都在同一个消费者组中,那么消息记录会被很好的均衡的发送到每个消费者实例,而如果在不同消费者组,则每一条消息都会被广播道每一个消费者实例
消费者组和分区间的关系:
同一个消费者组中,每个消费者实例可以消费多个分区,但是每个分区最多只能被消费者组中的一个实例消费,而每个分区可以被不同的消费者组消费。
- 为什么Kafka要在topic中加入分区的概念?
topic是逻辑的概念,而partition是物理概念,对用户来说是透明的,producer只需要关心数据发往哪个topic,而consumer只需要关心自己订阅哪个topic,而不需要关心每条信息存在哪个集群的哪个broker
如果topic内的消息只存到一个borker里,则会使得单机(单个broker)成为性能瓶颈,无法水平扩展,所以设计partition就是为了把topic的数据分布到整个集群,解决水平扩展问题的一个方案。
clickHouse
列式数据库
Prometheus + grafana
Prometheus是现在常用的云原生监控系统,与传统的相比,是基于中央化的规则计算、统一分析和告警的新模型
所有采集的监控数据均以指标(metric)的形式保存在内置的时间序列数据库当中(TSDB),所有的样本除了基本的指标名称以外,还包含一组用于描述该样本特征的标签
http_request_status{code='200',content_path='/api/path',environment='produment'} => [value1@timestamp1,value2@timestamp2...]
每一条时间序列由指标名称(Metrics Name)以及一组标签(Labels)唯一标识,每条时间序列按照时间的先后顺序存储一系列的样本值
表示维度的标签可能来源于你的监控对象的状态,比如code404或者content_path=/api/path,也可能来源于你的环境定义,比如environment=produment。基于这些Labels可以方便地对监控数据进行聚合,过滤,裁剪。
优点:
- 高效
对于监控系统而言,大量的监控任务必然导致有大量的数据产生,而Prometheus可以高效地处理这些数据
对于单一Prometheus Server实例而已可以处理:
- 数以百万的监控指标
- 每秒处理数十万的数据点
架构
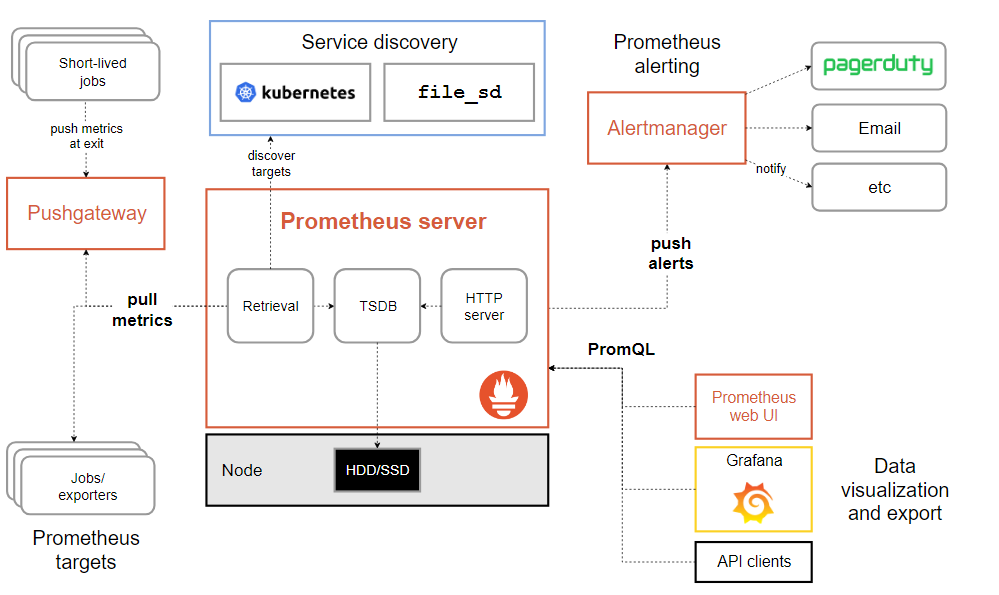
主要模块包括,Server,Exporters,Pushgateway,PromQL,Alertmanager,WebUI等
逻辑如下:
- Prometheus server 定期从静态配置的 targets 或者服务发现的 targets 拉取数据。
- 当新拉取的数据大于配置内存缓冲区时,Prometheus 会将数据持久化到磁盘(如果使用
remote storage将持久化到云端) - Prometheus 可以配置 rules,然后定时查询数据,当条件触发时,会将
alert推送到配置的Alertmanager - Alertmanager 收到警告时,可以根据配置,聚合,去重,降噪,最后发送警告
- 可以使用 API,Prometheus Console 或者 Grafana 查询和聚合数据
数据模型
时序索引
time series时序,是由名字(Metric),以及一组key/value标签定义的,具有相同的名字以及标签属于相同时序
时序的名字一般表示一个可以度量的指标,例如: http_request_total,可以表示 http 请求的总数
时序的标签可以使得 Prometheus 的数据更加丰富,能够区分具体不同的实例,例如http_requests_total{method="POST"} 可以表示所有http中的POST请求
标签名称由ASCII字符,数字以及下划线组成,其中 __开头属于 Prometheus 保留,标签的值可以是任何 Unicode 字符,支持中文。
时序样本
按照某个时序以时间维度采集的数据,称之为样本,其值包含:
- 一个float64值
- 一个毫秒级的 unix 时间戳
格式
<metric name>{<label name>=<label value>,...}
其中包含时序名字以及时序的标签
类型
时序共有四种类型,分别是Counter,Guage,Histogram,Summary
- Counter
Counter 表示收集的数据是按照某个趋势(增加/减少)一直变化的,我们往往用它记录服务请求总量、错误总数等.
eg. http_requests_total,表示Prometheus处理的http请求总数,可以使用delta,很容易得到任意区间数据增量
- Guage
搜集的数据是一个瞬时的值,与时间没有关系,可以任意变高变低,往往可以用来记录内存使用率、磁盘使用率等
eg. Prometheus中的go_goroutines表示 Prometheus当前 gorouutines 的数量
- Histogram
由<basename>_bucket{le="<upper inclusive bound>"},<basename>_bucket{le="+Inf"},<basename>_sum,<basename>_count组成,主要用于表示一段时间范围内对数据进行采样(通常是请求持续时间或响应大小),并且能够对其指定区间以及总数进行统计,通常数据展示为直方图
eg. Prometheus server 中 prometheus_local_storage_series_chunks_persited,表示 Prometheus 中每个时序需要存储的 chunks 数量,我们可以用它计算待持久化的数据的分位数
- Summary
由<basename>{quantile="<φ>"},<basename>_sum,<basename>_count组成,主要用于表示一段时间内数据采样结果(通常是请求持续时间或响应大小),它直接存储了quantile数据,而不是根据统计区间计算出来的
eg. Prometheus server 中的 prometheus_target_interval_length_seconds
PromQL
Prometheus的查询语言,通过PromQL可以实现对监控数据的查询、聚合,同时PromQL也被应用于数据可视化(例如Grafana)以及告警当中
- Counter
只增不减的计数器,可以在应用程序中记录某些事件发生的次数,通过以时序形式存储这些数据,我们可以轻松的了解该事件产生速率的变化,PromQL中也有内置一些聚合操作和函数
eg.
-
rate()获取HTTP请求量的增长率:
rate(http_requests_total[5m]) -
topk()获取访问量前10的HTTP地址:
topk(10,http_requests_total) -
Guage
可增可减的仪表盘
侧重于反应系统的当前状态,对于该类指标,通过PromQL内置函数delta()可以获取样本在一段时间返回内的变化情况。
eg.
-
delta()获取样本在一段时间返回内的变化情况计算CPU温度在两个小时内的差异
delta(cpu_temp_celsius{host="zeus"}[2h]) -
deriv()计算样本的线性回归模型 -
predict_linear()对数据的变化趋势进行预测预测系统磁盘空间在4个小时之后的剩余情况
predict_linear(node_filesystem_free{job="node"}[1h],4 * 3600)
查询时间序列
- 可以直接使用指标名称
http_requests_total
等价于 http_requests_total{},会返回所有指标名称为http_requests_total的所有时间序列
支持两种匹配模式,完全匹配和正则匹配
http_requests_total{instance="localhost:9090"}携带条件查询
正则匹配的话则使用 ~= 来表示 !~进行排除
- 范围查询
前面的其实是瞬时查询,返回结果称为瞬时向量,而相应的这样的表达式称之为_瞬时向量表达式
http_request_total{}[5m]
- 时间位移操作
不以当前时间为基准
http_request_total{} offset 5m 获得五分钟前的瞬时数据
http_request_total{}[1d] offset 1d 昨天一天的区间样本数据
- 聚合查询
sum(http_request_total) avg(node_cpu) by (mode)
按照主机查询各个主机的CPU使用率
sum(sum(irate)(node_cpu{mode!='idle'}[5m])) / sum(irate(node_cpu[5m]))) by (instance)
etcd
可信赖的分布式键值存储服务,为整个分布式集群存储一些关键数据,协助分布式集群的正常运转,使用Raft算法,一般部署推荐奇数个节点,因为是选举算法。
应用场景
- 服务发现
分布式系统中最常见的问题之一,即在同一个分布式集群中的进程或服务,如何找到对方并与之建立连接,本质上说就是想要了解集群中是否有进程在监听udp或tcp端口,并且通过名字可以查找和连接。
- 配置中心
将一些配置信息放到etcd上进行集中管理,这类场景的使用方式通常是在应用启动时主动从etcd获取一次配置信息,并且在etcd节点上注册一个Watcher等待,以后每次配置更新时etcd都会实时通知订阅者,以获得最新配置。
- 分布式锁
因为etcd使用Raft算法保持了数据的强一致性,某次操作存储到集群中的值必然是全局一致的,所以很容易实现分布式锁,锁服务有两种使用方式,一是保持独占,二是控制时序
- 保持独占:即所有获取锁的用户最终只有一个可以得到,etcd为此提供了一套实现分布式锁原子操作
CAS的API,通过设置prevExist值,可以保证在多个节点同时取创建某个目录时,只有一个成功,而创建成功的用户就可以认为是获得了锁 - 控制时序,即所有想要获取锁的用户都会被安排执行,但是获得锁的顺序也是全局唯一的,决定了执行顺序,etcd也提供了一套API(自动创建有序键),对一个目录建值时指定为
POST动作,这样etcd会自动在目录下生成一个当前最大的值为键,存储这个新的值(客户端编号),同时还可以使用API按顺序列出所有当前目录下的键值,此时这些键的值就是客户端的时序,而存储的值可以代表客户端编号。
grpc
四种通信模式
- 一元RPC
又称简单RPC,客户端发送请求到服务端,并获得一个响应,与响应一起发送的还有状态细节以及trailer元数据。
- 服务器端流RPC
一次请求,多个返回,比如搜索匹配项,客户端提供一个搜索词,服务端每搜索到一个匹配项就返回一个,这样可能就会有多个响应,通过rpc的returns(stream struct)来定义服务器端流
-
客户端流RPC
多个请求,一次返回 -
双向流RPC
多个请求多个返回
分布式
分布式系统是计算机程序的集合,这些程序利用跨多个独立计算节点的计算资源来实现共同的目标。
Zinx
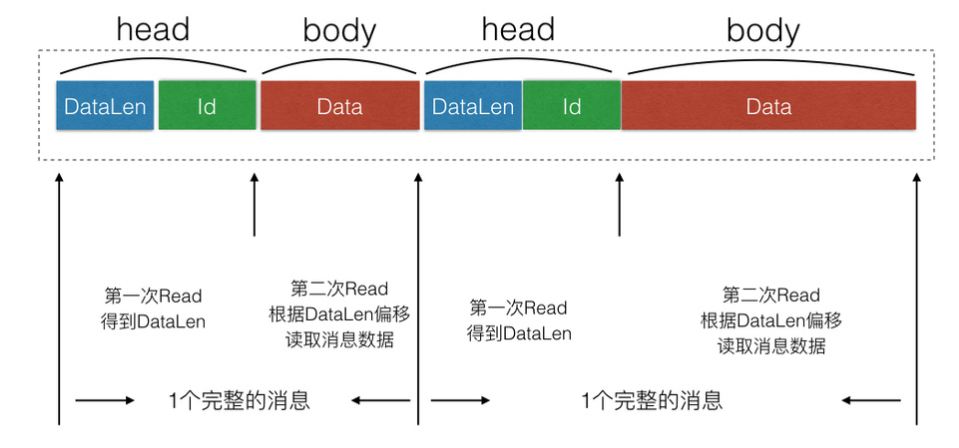
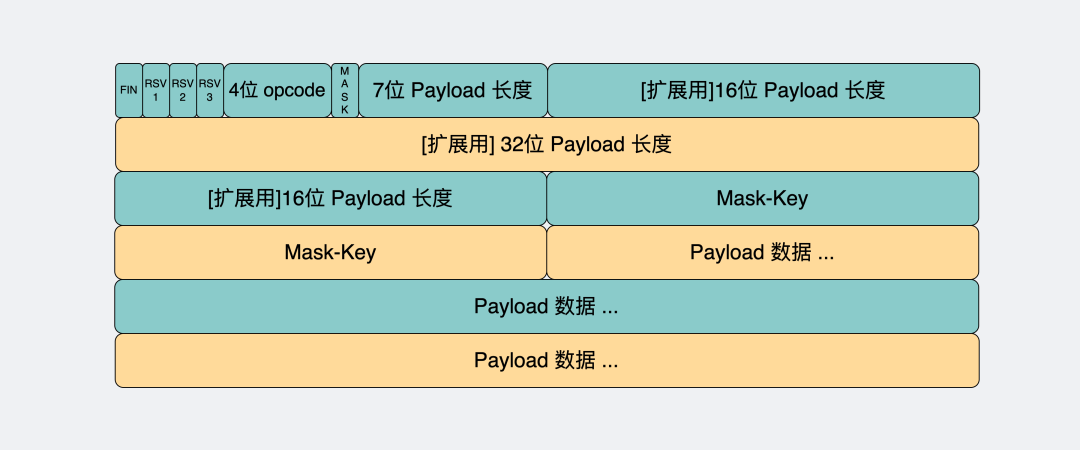
消息封包和拆包如何解决的
采用了最经典的TLV(Type-Len-Value)封包格式解决了粘包问题
计算机网络
OSI七层模型
- 应用层
- 会话层
- 表示层
- 传输层
- 网络层
- 数据链路层
- 物理层
HTTP
超文本传输协议 HyperText transfer protocol
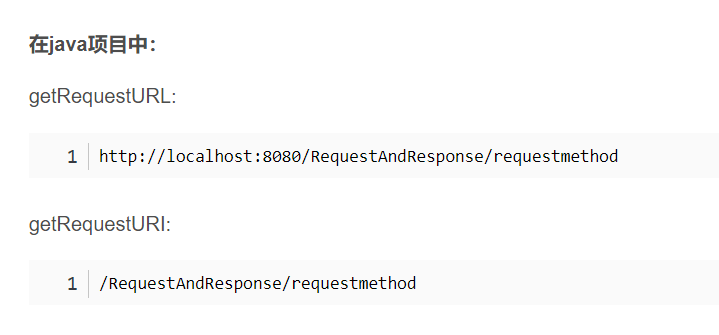
URL和URI的区别
- URL:Uniform Resource Locator
统一资源定位定位符
- URI:Uniform Resource Identifier
统一资源标识符
URL是URI的子集,看下面这张图,其实有点可以这样认为,URI是一个资源的标识,而URL还要标识这个资源的具体位置。
跨域
先了解一下Options,浏览器在发起复杂请求前会自动发起 options 请求,即一个预检请求,从而获知服务端是否允许该跨域请求,服务器确认允许后才发送真的http请求。
再了解一个名词,同源,即域名、协议、端口都相同即同源。
而非同源之间的网络调用就是跨域
GET和POST的区别
- GET是从指定路径获取资源和数据,POST是提交要被处理的数据
- GET的参数会显示在URL上,POST通过表单提交不会显示在URL上
- GET请求会被缓存,且请求会保留在浏览器历史记录中,而POST都不会
- GET请求有长度限制(主要是受到URL长度限制),POST请求则没有要求
- 编码方式不同,GET请求只能进行URL编码,而POST请求支持多种编码方式,包括二进制方式
options带来的问题
每次复杂请求都需要一个预检请求,如果是高并发的话会有不必要的网络资源消耗,影响了性能,所以需要优化
Access-Control-Max-Age参数就可以优化这个流程,即一次options后,接下来对应ns的时间里都支持,这段时间内不需要再来一次options请求了
相关信息
localhost和127.0.0.1非同源
状态码
-
1xx
接受的请求正在处理
- 101 Switching Protocols:服务器即将切换协议
- 102 Processing:服务器已收到并正在处理该请求,但没有响应可用
-
2xx
请求正常处理完毕
- 200 OK 请求正常处理
- 204 No Content:请求处理成功,但没有任何资源可以返回给客户端
- 206 Partial Content:是对资源某一部分的请求,该状态码表示客户端进行了范围请求,而服务器成功执行了这部分的GET请求,响应报文中包含由Content-Range指定范围的实体内容
-
3xx
重定向状态码
- 301 Moved Permanently:永久重定向
- 302 Found: 临时重定向
- 303 See Other:资源URI已更新,该状态码表示请求对应的资源存在另外一个URL,303与302的区别是需要用GET获取资源
-
4xx
客户端错误状态码
- 400 Bad Request:服务端无法理解客户端发送的请求
- 401 Unauthorized:该状态码表示发送的请求需要通过认证
- 403 Forbidden:表明对请求资源的访问被服务器拒绝了(权限,未授权IP等)
- 404 Not Found:找不到资源
-
5xx
服务器错误状态码
- 500 Internal Server Error:服务器错误
长连接
-
Connection
表示请求响应完成之后立即关闭连接,HTTP/1.0请求的默认值 -
Connection
表示连接不立即关闭,而是可以复用,HTTP/1.1的请求默认值
注意:长连接也需要设置有超时时间,否则长连接过多不释放也会影响性能,占用资源过多
Cookies
cookies是浏览器请求后服务端返回的一段数据,里面一般是携带该浏览器的身份信息,浏览器收到后会保存这段数据,此后每次访问服务器都会携带这份数据,服务端则用该cookies来判断浏览器身份
- 作用
-
身份识别
-
持久化用户信息
可以将一些用户信息放入cookies中,然后返回浏览器,进行一些个性化展示,不过实际上不是很经常用这种方法
浏览器缓存
HTTPS协议
这个可以去看前面的另外一篇文章
了解HTTPS
HTTP建立连接比较简单,只需要三次握手即可进行HTTP报文传输,而HTTPS还需要在三次握手后建立SSL/TLS的握手过程,才可进入加密报文传输。
HTTPS主要解决的是HTTP的明文传输问题
HTTPS的建立流程:
- SSL/TLS协议基本流程
- 客户端向服务器索要并验证服务器的公钥
- 双方协商生产
会话密钥 - 双方使用
会话密钥来进行加密通信
TLS握手涉及四次通信,不同密钥交换算法TLS握手流程不一样,现在常用的有两种
- RSA算法
- ECDHE算法
- ClientHello
首先由客户端向服务端发起加密请求
- 发送客户端支持的TLS协议版本
- 生成一个随机数(Client Random),后面用于生成
会话密钥 - 客户端支持的密码套件列表,如RSA算法
- ServerHello
服务端收到客户端请求后,向客户端发出响应,即ServerHello,服务器回应:
- 确认使用的TLS协议版本,如果浏览器不支持,则关闭加密通信
- 服务器生成一个随机数(Server Random)
- 确认使用的密码套件列表
- 服务器的数字证书
- 客户端回应
客户端收到服务端回应后,通过浏览器或者操作系统中的CA公钥,确认服务器的数字证书真实性,如果没问题,则取出公钥,然后加密报文,向服务器发送:
- 一个随机数(pre-master key),该随机数会被服务器公钥加密
- 加密通信算法改变通知,表示随后的信息都用
会话密钥加密 - 客户端握手结束通知,同时把之前的所有内容的发生的数据做个摘要,用来供服务端校验
服务端和客户端有了这三个随机数,就用双方协商的加密算法生成本次通信的会话密钥
- 服务器回应
服务器收到了第三个随机数,生成密钥,然后向客户端发送最后的信息
- 加密算法改变通知,表示随后的信息都用
会话密钥加密 - 服务端握手结束通知,并把之前所有内容的发生的数据做个摘要,供客户端校验
不过RSA算法存在一个问题,即向前安全问题,如果私钥泄漏了,过去被截取的所有通讯密文都会被破解,所以又诞生了ECDHE密钥协商算法
HTTPS还是可能会遇到中间人攻击的,比如有一个中间服务器截取了请求,然后既与客户端建立连接,又与服务端建立连接,消息正常发送,双方都不会发现错误,但出现这个问题的情况是用户选择了信任了非法的证书,因为中间服务器是伪造的证书,所以并非是HTTPS的问题,而是客户端的漏洞导致的。
HTTP/1.1如何优化
- 避免发送HTTP请求
对于一些具有重复性的HTTP请求,比如每次请求得到的数据都不一样,我们可以把这对请求-响应缓存到本地,下次就可以直接读取本地的数据,不必通过网络获取服务器的响应。
即强缓存和协商缓存
- 减少HTTP请求次数
- 减少重定向请求次数
每次重定向都需要先请求一次源地址,获得302响应后再去发送新地址的请求来获取服务器资源,那么就每次都增加了请求的次数,降低了网络性能
如果重定向的工作交由代理服务器完成,就能减少HTTP请求次数
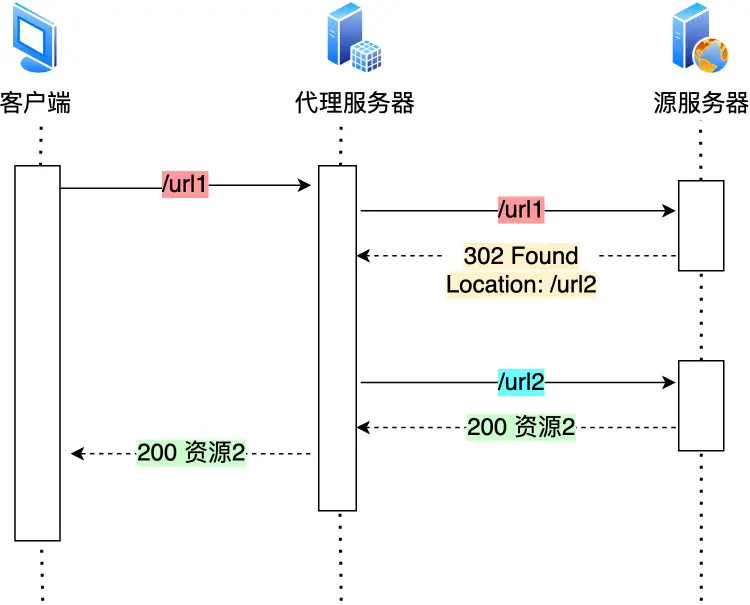
- 合并请求
如果把多个访问小文件的请求合并为一个大的请求,虽然传输的总资源不变,但是减少了请求意味着减少了重复发送的HTTP头部
而且由于HTTP/1.1的请求响应模型(管道默认不开启),为了防止单个请求的阻塞,一般浏览器会同时发送5-6个请求,每一个请求都是不同的TCP连接,那么如果合并了请求,就会减少TCP连接的数量,省去了TCP握手和慢启动过程消耗的时间。
合并的方式:
比如网页中的多个图片,图标等,可以考虑用CSS Image Sprites合并成一个大图片,这样浏览器就可以用一次请求获得一个大图片,然后再根据CSS数据把大图片切割成多张小图片
但是这样的合并请求有一个问题,即大资源中某个小资源发生变化,客户端需要重新下载完整的整个大资源文件。
- 延迟发送请求
一般HTML里包含多个URL,不要一次性全部获取,可以按需获取来减少第一时间的HTTP请求次数,只有当用户需要对应数据才来获取
- 减少HTTP响应的数据大小
- 无损压缩
例如gzip
- 有损压缩
TCP/IP层
TCP的作用是保证网络数据包的可靠性,因为IP是不可靠的,不保证网络包的按序交付和网络包中数据的完整性
消息在进入四层模型时(应用层,传输层,网络层,网络接口层),都会在每一层加上一个报头,这个报头一般是记录接下来要去哪里的信息,以及消息长度,比如网络接口层就会加上一个mac头部
MTU 和 MSS
-
MTU: Max Transmit Unit
最大传输单元,由网络接口层(数据链路层)最大一次传输数据的大小,一般MTU=1500Byte -
MSS:Max Segment Size
TCP提交给IP层最大分段大小,不包含 TCP Header 和 TCP Option,只包含 TCP Payload,MSS是TCP用来限制应用层最大的发送字节数
粘包
由于上面MTU和MSS的限制,而且我们都知道TCP是基于字节流的,所以如果一条消息过长,就需要将他拆分开来分多次发送,每次最大分为一个MSS大小。等接收端接收到后再来进行拼接,重新组合成原先的一条消息
那么问题来了,都说是基于字节流的,即消息之间没有界限,那么一次性拿出对应MSS长度的字节去拼接一条消息,就有可能会分别取了两条消息的各一部分进行拼接,那么接收端该如何解析呢?就现在已有的方法,接收端貌似无能无力,那么就可能会出现粘包现象。
为什么要组装
那问题来了,为什么要组装消息,可不可以就是这条消息1760byte,那这时就分两条发送,先发1460,再发剩下的,这样不就好了?
那最明显的问题就是会浪费网络IO,因为这样的话就是每有消息就要发送,那么如果消息只有几个字节,每次都单独发送就不是很好。
也是针对这个问题,有了Nagle算法
Nagle算法
算法的目的是为了避免发送小数据包
- 如果长度达到 Mss(或者含有Fin包),则立即发送,否则会等待下一个包,如果下一个包到来后,两者总长度超过MSS,就会进行拆分发送
- 等待超时,如果第二个包迟迟没来,则立即发送
那有人又认为关掉Nagle算法是不是就不会粘包了?
Nagle是很久前的算法了,如今网络环境好了很多,所以现在一般都会把它关掉,而保证消息传输的实时性,但是在现在粘包问题还是存在的,所以关闭它并不能解决这个问题
其实还有个情况就是,接收端接收到msg1后来不及取走,而这时候msg2马上又到了,粘包问题不就又出现了?而这时是没开启Nagle算法的。
如何解决
粘包出现的问题就是字节流没法确定消息边界,那么能不能人为添加一个边界,这时候很容易就想到约定一个特殊符号作为边界来区分,或者是加入一个消息的长度来区分,这样是两种常用的方法。可以取参考HTTP如何解决的,一般两者一起使用。
而约定的边界标识也有可能是消息的一部分,所以常常还需要各种校验字段来验证发过来的是完整消息,而且可以采用类似转义字符的方法来解决。
粘包出现的原因其实就是因为字节流无法区分消息的边界,粘包不是TCP的问题,而是使用者对TCP理解有误导致的问题
所以使用者可以在发送端每次发送时给消息带上识别消息边界的信息,接收端就可以根据这些信息识别出消息的边界,从而区分出每个消息
- 加入特殊标志
比如加个回车符则认为是收到了新消息的头,就往后读取直到读到下一个尾部标记才是一个完整消息,但是也有可能传输的消息就是该特殊符号,这时候就需要使用转义字符的思想了,或者就是发送端在发送时会加入各种校验字段(校验和或者对整段完整数据进行CRC之后获得的数据)放在标志位后,在接收端拿到整个数据后校验下确保它就是发送端发来的完整数据。
- 加入消息长度信息
一般配合特殊标志一起使用,在收到头标志时,里面可以带上消息长度,表明在此之后多少byte都是属于这个消息,如果在此之后有符合长度的byte,则之间取走做为一个完整消息,就像HTTP的Content-Length一般。
UDP会粘包吗
UDP是基于数据包的网络传输协议,我们前面总说粘包是因为基于字节流,那么UDP它会有粘包的问题吗
User Datagram Protocol,用户数据包协议
面向无连接 不可靠 基于数据报的传输层通信协议
前面都在说TCP的粘包,那么UDP会粘包吗?
基于数据报,其实就是无论应用层交给UDP多长的报文,UDP都照常发送,如果数据包太长需要分片,UDP也不处理,而是由IP层来处理,这样会保留报文的边界
了解TCP和UDP文章
TCP/UDP头部
TCP和UDP区别
- 连接
TCP是面向连接的,UDP是不需要连接,即刻传输数据
- 服务对象
- TCP是一对一,一个服务只有两个端点
- UDP是一对一、一对多、多对多的交互通信
- 可靠性
- TCP是可靠交付数据,数据无差错、不丢失、按序到达
- UDP是尽最大努力交付,不保证可靠交付数据,但是可以基于UDP传输协议实现一个可靠的传输协议,比如QUIC协议
-
拥塞控制、流量控制
TCP具有以上机制保证数据传输的安全性,而UDP没有,无论网络情况如何,都不会影响UDP的发送速率 -
首部开销
- TCP首部较长,开销会相对较大,没有使用选项字段时时20个字节,如果使用了选项字段会变长
- UDP首部只有8字节,并且固定不变
- 传输方式
- TCP流式传输,没有边界,但可以保证顺序和可靠
- UDP以包为单位传输,有边界
- 分片不同
-
TCP数据大小如果小于MSS,则会在传输层进行分片,目标主机收到后,也会同样在传输层组装TCP数据包,如果中途丢失了一个分片,只需要传输丢失的这个分片
-
UDP数据大小如果大于MTU,则会在IP层进行分片,目标主机收到后,在IP层组装完数据,接着再传给传输层
-
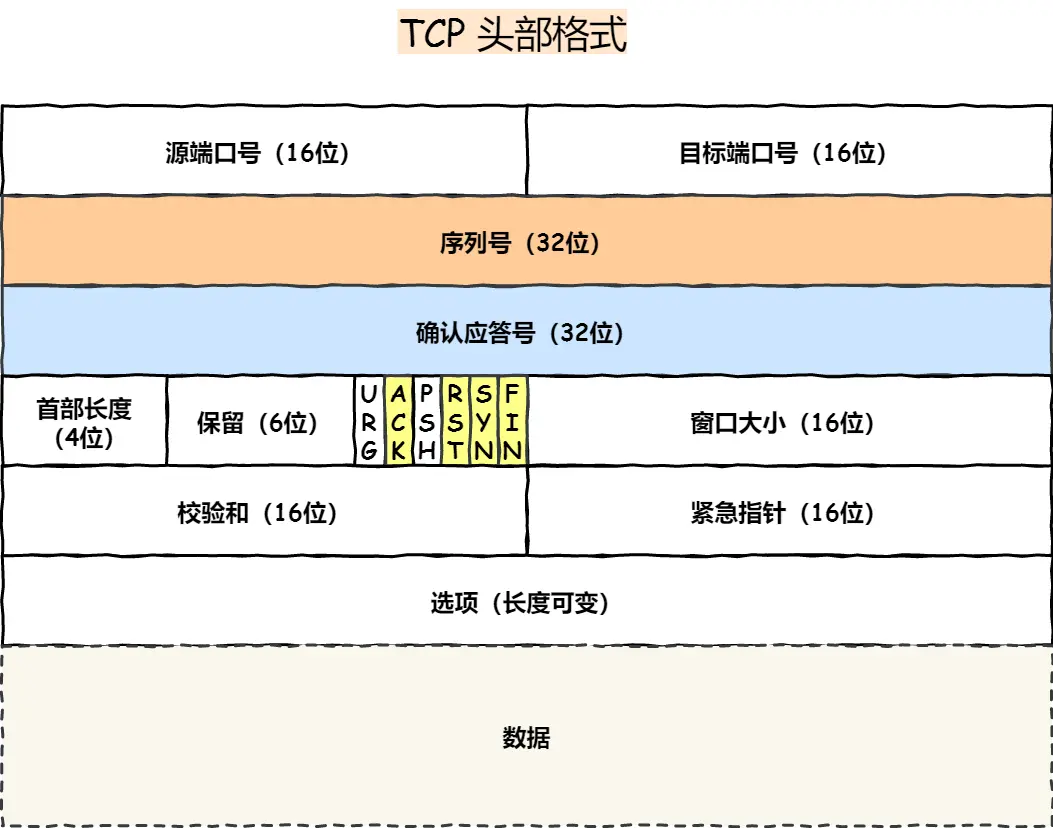
序列号:
建立连接时由计算机生成的随机数作为其初始值,通过SYN包传给接收端主机,每发送一次数据就累加一次该数据字节数的大小,用来解决网络包乱序问题
- 确认应答号
指下一次期望收到的数据的序列号,发送端在收到这个确认应答以后可以认为在这个序号以前的数据都已经被正常接收,用来解决丢包问题
- 控制位
- ACK:为1时确认应答字段有效,除了最初建立连接时的SYN包以外都得设置为1
- RST: 为1时表示TCP连接中出现异常必须强制断开连接
- SYN:为1时表示希望建立连接,并在其序列号字段进行序列号初始值设定
- FIN:为1时表示之后不会再有数据发送,希望断开连接。
UDP
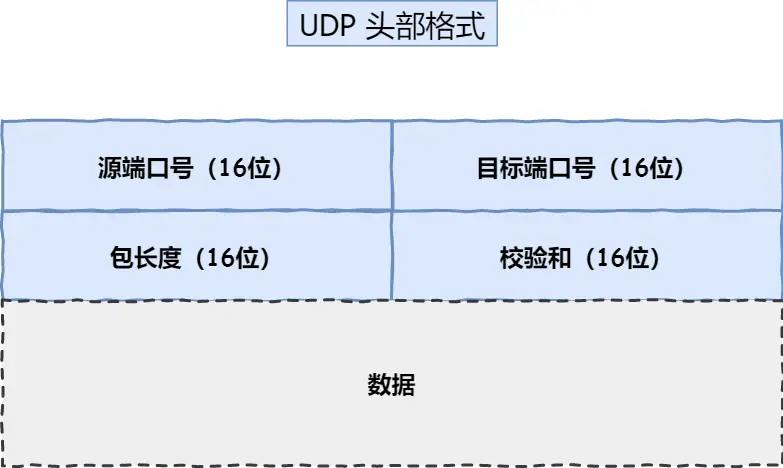
- 目标和源端口:主要是告诉 UDP 协议应该把报文发给哪个进程。
- 包长度:该字段保存了 UDP 首部的长度跟数据的长度之和。
- 校验和:校验和是为了提供可靠的 UDP 首部和数据而设计,防止收到在网络传输中受损的 UDP 包。
常见问题
如何确定一个TCP连接
一个四元组:源ip,源端口,目的ip,目的端口
TCP和UDP可以共用一个端口吗
可以,因为端口是区分同一个主机上不同应用程序的数据包,但是TCP/UDP在内核中是两个完全独立的软件模块,当主机收到数据包后,可以在IP包头的协议号字段去查看使用协议,然后再确定消息发送的模块。
为什么TCP是3次握手
我们要知道,
HTTP不同版本
- HTTP/1.1
提出了长连接的通信方式,也叫持久连接,避免跟HTTP/1.0一样,每次请求都要简历一个新的连接,而且串行请求,做了无所谓的TCP连接建立和断开,增加通讯开销。
还新增了管道(pipeline)网络传输,即在同一个TCP请求中,可以发起多个请求,不必等待响应就可以发送第二个请求,可以减少整体的响应时间。
但仍存在一个问题,即服务器必须按序响应接收请求,那么如果前面的请求处理时间较长,则会阻塞后面的请求,称为队头阻塞,HTTP/1.1只解决了请求的队头阻塞,但是没有解决响应的队头阻塞。
而且HTTP/1.1还有性能瓶颈:
-
请求/响应未经压缩就发送,首部信息越多延迟越大,只能压缩
body部分 -
冗长的首部每次互相发送相同的首部造成的资源浪费较大
-
没有请求优先级控制
-
请求只能从客户端开始,服务端只能被动响应
-
HTTP/2.0
HTTP/2.0协议是基于HTTPS的,所以安全性是有保障
相比前面的版本有了以下改进:
- 头部压缩
- 二进制格式
- 并发传输
- 服务器推送
- 头部压缩
如果同时发出多个请求,他们的头是一样的或相似,那么协议会帮忙消除重复的部分,即HPACK算法,在客户端和服务器同时维护一张头信息表,所有字段都会存入这个表中,生成一个索引号,以后就不发生同样字段,只发生索引号即可
- 二进制格式
全面采用了二进制格式,头信息和数据体都是二进制,并且称为帧:头信息帧和数据帧
这样收到报文后无需再进一步转化,而是直接解析二进制报文,增加了数据传输的效率
-
并发传输
HTTP/1.1是基于请求-响应模型,而HTTP/2引入了Stream的概念,多个Stream复用同一个TCP连接 -
服务器推送
server push,服务端可以主动向客户端发送消息
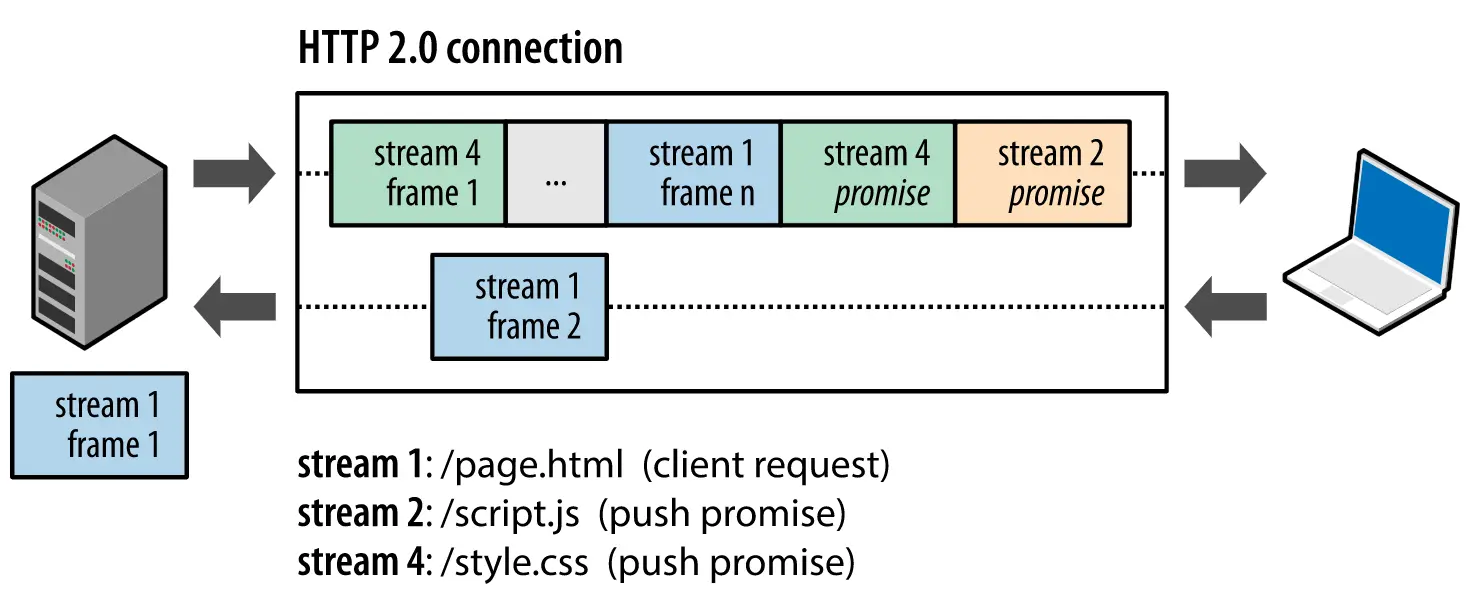
- HTTP2缺陷
解决了1.1的队头阻塞,但是还是有这个问题,只不过是在TCP层的问题了
TCP是字节流协议,必须保证收到的字节数据是完整且连续的,所以当前一个字节数据没有到达时(丢包),后收到的字节数据只能存放在内核缓冲区中,只有等到该字节数据到达时,应用层才能从内核中拿出数据。
- HTTP/3.0
基于UDP协议
HTTP和RPC区别
RPC又称远程过程调用,不是一个具体的协议,而是一种调用方式
区别:
- 服务发现:
首先要向某个服务器发起请求,得先建立连接,而建立连接的前提是得知道IP地址和端口,这个找到服务对应的IP端口过程就是服务发现
在HTTP中,一般是知道服务的域名,然后通过DNS服务区解析得到背后的IP发起请求
而RPC,则有专门的中间服务去保存服务名和IP信息,想要访问某个服务,就去这些中间件服务去获得IP和端口信息,DNS也是服务发现的一种,例如CoreDNS就是基于DNS去服务发现的组件
- 底层连接形式
HTTP/1.1默认是建立底层TCP连接之后保持这个连接不断开(Keep Alive)
而RPC和HTTP类似,也是通过建立TCP长连接进行数据交互,但是RPC协议一般还会再建个连接池。
- 传输的内容
HTTP是一个标准统一的协议,所以需要考虑的东西更多,所以其消息头和消息体所携带的东西会更多,一般是用JSON来保存
而RPC定制化程度更高,可以采用体积更小的Protobuf或其他序列化协议去保存结构体数据
HTTP和Websocket
我们有时候需要做到由服务端主动来推送消息给客户端,有几种常见的方法
- HTTP轮询
我们平常都是客户端请求服务端来响应,服务端是被动的发送消息,而可以基于这个模拟服务端推送,其实也算不上服务端推送,因为还只是普通的响应罢了,只不过这个请求对于用户无感,所以能得到一种类似服务端推送的效果
扫码登录是一种常见的使用场景:前端无法得知用户是否有扫码,于是需要不断去向后端服务器轮询,查看是否有扫码
- 缺点
请求过多,增加服务器消耗
每个请求之间有间隔,例如扫码,可能设计1-2s轮询一次,则可能会在2s后才得到响应,体现在用户端就是卡顿
- 长轮询
HTTP发出请求后,会有一段超时时间,如果把这个超时时间设置的很大,那么在这段时间内,收到了扫码请求,就会立马返回给客户端网页,如果超时,那么就立马发起下一次请求
- Websocket
TCP是全双工的,但是HTTP协议中,常常是半双工的,因为HTTP协议的设计只是考虑简单的BS架构,网页之类的场景,只需要请求响应模型就够了,而没有考虑到例如游戏这种场景,所以为了更好地支持这样的场景,就需要基于TCP设计一个新的协议,于是又有了websocket
为了兼容两个协议切换的使用场景,浏览器在TCP三次握手建立连接后,都统一使用HTTP协议进行一次通信,如果想建立ws连接,则在HTTP请求中带上一些特殊的头
Connection: Upgrade Upgrade: WebSocket Sec-WebSocket-Key: Tsadsajd
即浏览器想升级协议为websocket协议,并且带上一段随机生成的base64码,如果服务器支持该协议,就会走ws的握手流程,同时根据客户端生成的base64码用某个公开的算法变成另外一段字符串,放在HTTP响应的Sec-WebSocket-Accept头里,同时带上101状态码,发回给浏览器,101是指协议切换。
之后浏览器也用同样的公开算法将base64转为另外一个字符串,如果这段字符串和服务器传回来的一致,那验证通过。
- 消息格式
操作系统
进程和线程
死锁
死锁产生的条件:
- 互斥条件
- 持有并等待
- 不可剥夺
- 环路等待
epoll
一般来说,实现处理tcp请求,为一个连接对应一个线程,但是在高并发的场景下,这种多线程模型与Epoll相比就显得相形见绌了,epoll是linux的一个新的系统调用,epoll在设计之初,就是未来替代select,poll线性复杂度的模型,其时间复杂度为O(1),即在高并发场景,随着文件描述符的增长,有良好的可扩展性。
实际问题
限流
随着微服务的流行,服务之间的依赖加深,为了防止某个服务的请求突增而给下游服务带来较大压力,往往需要采取方法来保证稳定性,往往就通过缓存、限流、熔断等级、负载均衡等多种方式保证。
限流即对请求或并发数进行限制,通过对一个时间窗口内的请求量进行限制保障系统正常运行。
- 阈值
在一个单位时间内允许的请求量,如QPS限制为10,说明1s内最多10此请求
- 拒绝策略
超过阈值的请求的拒绝策略,如直接拒绝、排队等待等
以下说一下几种常见的限流方法
固定窗口算法
又称计数器算法,就是一个支持原子操作的计数器来累计1s内的请求次数,到达阈值时触发拒绝策略,过了1s则重置。
滑动窗口算法
固定窗口很好实现,但是存在比较大的问题,比如在0-0.9s的时候没有请求,而0.9-1s的请求刚好到达了阈值,而1s-1.1s的时候请求也达到了阈值,1.1-2s又没了请求,这样是不会触发拒绝策略的,但是实际上呢,在0.5-1.5这1s内QPS其实是远远大于阈值的,所以就有了滑动窗口进行改进。
那就改成比如500ms滑动一次窗口,只要滑动的间隔较短,临界突变发生的概率也就越小,不过只要有窗口存在就仍然有可能发送该问题。
滑动日志算法
逻辑就是记录下每个请求的时间点,如果新请求到达的时候就去判断时间范围内的请求数量是否超过阈值,但是这样每次请求都要记录时间点,请求多的时候需要很大的内存
漏桶算法
这一个和令牌桶是比较重要的。
请求看成生产者,每个请求如同一滴水,放到一个队列里(漏桶),而底部有一个孔,会不断的漏出水滴,消费的速率等于阈值,例如QPS=2,则消费速率为1s/2=500ms,当请求堆积超出指定容量触发拒绝策略。
缺点是因为消费速率固定,如果漏桶接近满的时候,无法一次性处理多个请求,只能按照QPS速率处理。
令牌桶算法
系统服务作为生产者,按照指定频率往桶中添加令牌,如QPS=2,则每500ms加一个,等到桶中令牌数据达到阈值则不再添加。
而请求执行为消费者,每个请求都需要携带一个令牌,没有则触发拒绝策略。
漏桶和令牌桶算法的区别
漏桶能够限制数据的传输速率
令牌桶则能够限制数据的平均传输速率,且允许某种程度的突发传输。
业务缓存设计
- 旁路缓存(Cache Aside)
- 主要针对强一致性,以db驱动cache,每次修改db都会直接写入db中,然后将cache删掉,采用lazy加载,等用到时才从db中加载出来,这样可以确保数据是以db为准的
- 读写穿透(read/write through)
- 适合数据有冷热区分的,cache不存在则直接更新db,存在则两者更新,比较常用的方法,但是需要保证数据一致性的话还需要另外操作,存在事务性的问题,例如,多个读取操作同时向缓存查找数据源,而数据源中的数据恰好被另外一个写入操作修改
- 异步缓存写入(Write Behind Caching)
- 适合写频率较高的,需要合并的操作,他先更新缓存,然后缓存服务再异步去更新DB,但是有个显著的缺点,即数据一致性变差,而且可能会丢失数据
分布式锁
RedLock
负载均衡
网关的负载均衡如何实现?
- 轮询(Round Robin):按照轮询的方式依次将请求分发给后端服务器,然后每个请求按照顺序依次分配给不同的服务器,循环往复,这种算法简单且均衡,适用于服务器性能相似且无状态的情况
- 最少连接(Least Connection):根据当前连接数选择连接数最少的服务器来处理新的请求,这种算法可以有效地将负载均衡到连接数较少的服务器上,以保持各服务器的负载相对均衡。
- IP哈希(IP Hash):根据客户端的IP地址进行哈希计算,将同一个IP地址的请求发送到同一个后端服务器,这样可以确保同一个客户端的请求都发送同一台服务器上,适用于需要保持会话一致性的场景
- 加权轮询(Weighted Round Robin):给每个服务器分配一个权重值,根据值的比例来分配请求,具有较高权重的服务器会接收到更多的请求,适用于服务器性能不均衡的情况
- 加权最少连接(Weighted Least Connection):根据服务器的当前连接数和权重值来选择服务器,连接数越少且权重值越高的服务器会被优先选择
- 随机(Random):随机选择一个后端服务器来处理请求,这种算法简单且均衡,但无法保证每个服务器的负载一致
- 响应时间加权(Response Time Weighted):根据服务器的平均响应时间或处理时间来分配请求,响应时间较短的服务器会得到更多的请求,以提高系统整体的响应进度。
防刷
秒杀
秒杀系统是电商中的常见业务模式,用于吸引用户,刺激留存及消费所做的一种活动,常见的是:整点秒杀、商品秒杀
特点
- 瞬时流量极大,过了秒杀时间点流量就结束,所以不能用机器堆QPS
- 秒杀商品库存极少,例如1w个用户去抢10个商品
- 秒杀时间点未到,刷新量极大,静态资源被访问剧增。
考虑
- 高并发,快响应
- 防止超卖
- 防刷子:防止机器人抢占订单
- 页面资源访问多:CDN、静态资源缓存及压缩
- 秒杀按钮:前端限制一些请求打到后端,按键置为灰
- 秒杀真链接隐藏:防止后台交互链接,非秒杀期间漏出
- 异步处理:秒杀成功后再提交订单处理服务
- 订单失败补偿:遇到订单后续处理失败,必须补偿
- 服务降级:遇到紧急情况,可以快速处理
解决
- redis+mq+资源缓存,负载均衡等,上线前需压测了解qps
- lua脚本,原子性保持流程,购买成功和订单减少一定是一致的
- 限流,一种是同一用户id限流,另外一种是同一ip限流,一般情况秒杀是热点数据,所以不担心限流影响体验,达到了阈值则一般是无法再抢到商品了。
- URL唯一化处理,保证用户直接请求url无需去解析请求头,无需重组http协议,可以直接找到姿态资源返回,不与后端进行数据交互,一般静态资源放到cdn上,可以提高响应速度和命中率。
- 未到时间不允许点击产生交互
- 防止请求链接被知道,而提前通过机器等方式进行提前请求,既带来了压力又影响正常体验,所以需要采取链接加密,每次秒杀无规律可言。
- mq的异步处理
- 报警机制等
- 业务降级,一般不采取,除非很严重事故。
缓存一致性
服务预热
在服务启动完成到对外提供服务之前,针对特定场景提供一些初始化准备操作,比如线程池预热、缓存预热、数据库预热等,避免首次请求产生较大的延迟
幂等性问题设计
幂等是接口可重复调用,且得到结果是一致的
- 幂等场景
例如sql,其实查询就是幂等的,虽说每次查询的返回结果不一样,但是实际上对系统造成的影响是一致的,所以也认为是幂等的
那插入呢,如果insert into table(userid,nums) values(1,2),且userid为主键,那么多次插入只有一条数据,那么也认为是幂等的,但是如果userid可重复,那么就会有多条数据了,不认为是幂等
如果是update,update user set nums = 20 where userid=1和update user set nums = nums + 20 where userid=1,那么前者是幂等的,后者就不是了
解决方法:
- token机制
原理其实就是多次针对同一个接口的请求,如果这样的请求有一个唯一凭证,每次这个凭证访问到后端,看看redis有没有,有的话请求执行,redis中删除凭证,没有的话请求失败,这样同样的2个请求可以保证第一次成功第二次失败。
其实就是例如在支付场景中,在用户点击支付之前颁发一个token,然后将这个token存到redis里,等接到请求时就携带这个token,去redis查询,查询的到则放行业务并删除token
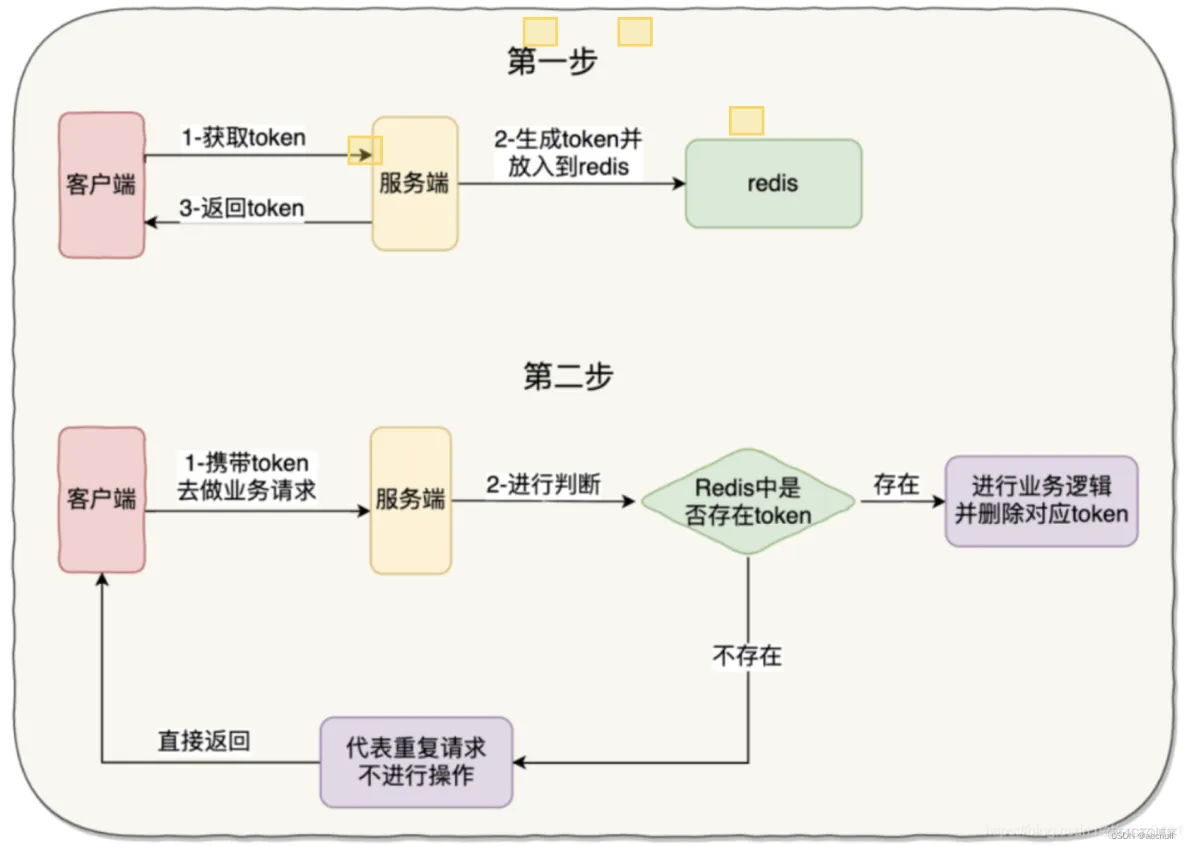
不过这种机制会增加了很多额外的请求。
-
乐观锁机制
-
唯一主键机制
利用了数据库的主键唯一约束的特性,解决了在insert场景时幂等问题,但主键要求不能是自增的主键,这样就需要业务生成全局唯一的主键,如果分库分表的情况下,就要保证相同请求要落地在同一个数据库和同一个表中
- 去重表机制
influxDB
时序数据库
存储引擎
LSM Tree(Log Structured Merge-Tree)
概念
- database 数据库
- measurement 表
- point 一行数据,包括时间戳,数据,标签
- time 每个数据记录时间,是数据库中的主索引
- fields 各自记录值(没有索引的属性)
- tags 有索引的属性
- series 数据库中的数据,需要通过图表来展示,表示表里面的数据,可以在图表上画成几条线,通过tags排列组合计算出来
dtm
分布式事务
Gorm
Gin
Websocket
Casbin
JWT
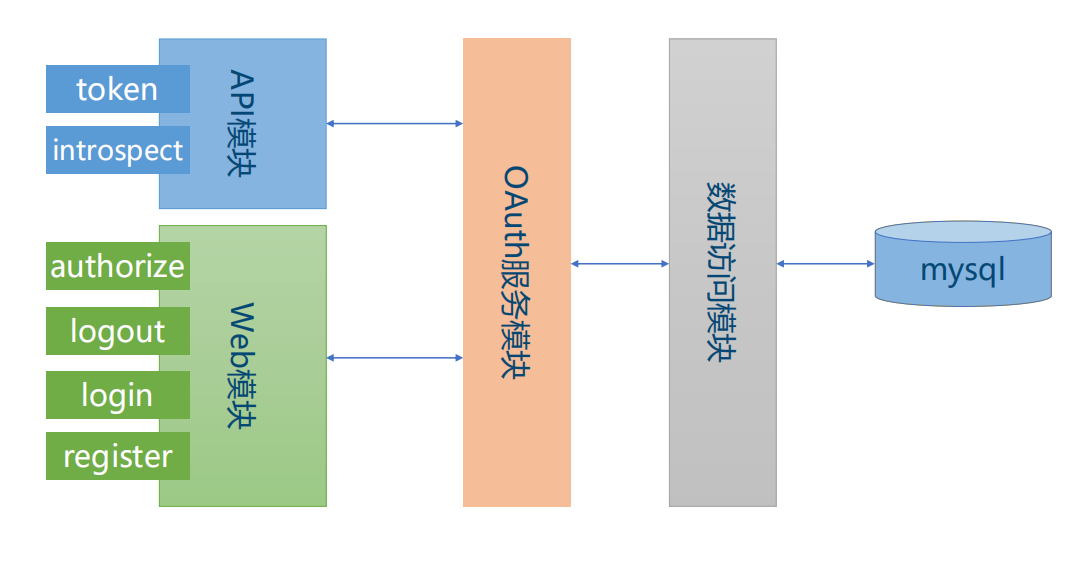
OAuth2
go-zero
mapreduce
实际业务场景中我们常需要从不同的rpc服务中去获取相应属性来组装成复杂对象,比如查询商品详情:
- 商品服务
- 库存服务
- 价格服务
- 营销服务
如果串行的话响应时间会随着rpc调用次数呈线性增长,所以一般会优化为并行
kitex
项目问题
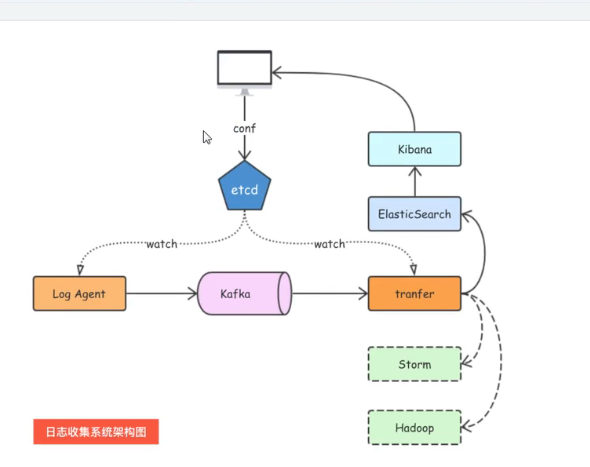
日志收集
常用的是ELK架构,但这里采用了另外的架构
Zinx
RPC项目
分布式缓存
- 介绍一下一致性哈希
对于分布式来说,一个节点接到请求,如果该节点并没有存储该缓存值,那么就需要从数据源来获取,但是每次请求选到的节点不一定一样,那么有可能缓存在1节点,但是下次不一定能选到1节点,那么就需要从数据源再获取一次,这样会使得缓存效率低,浪费大量的存储空间,所以需要选择一个方法来解决,对于给定的key,每一次都选择同一个节点
最简单的就是自定义哈希,对于每个key设置自己的hash函数,然后使其能映射到某一个节点上,但是存在一个问题,就是如果节点变化了,那么就没法准确的映射到对应节点了
所以这里使用一致性哈希算法
- 原理
将key映射到2^32的空间中,将这个数字首尾相连形成一个环,计算节点的哈希值,放入环上,然后计算key的哈希值,放置到环上,然后顺时针找到第一个节点,就是要选择的节点,这样每当新增一个节点,就只有附近的几个key需要重新寻找节点。
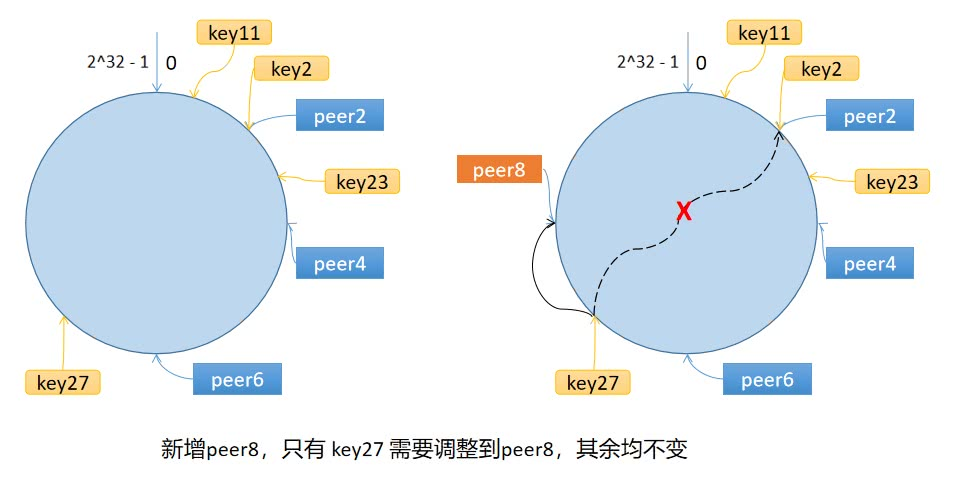
- 数据倾斜问题
我们环的空间是不变的,当节点太少时,可能会出现大部分节点都在一边,而另外一部分节点过少,则使得会有大部分下半部分的key分配到同个节点上,缓存节点间负载不均衡。
所以引入了虚拟节点的概念,一个真实节点对应多个虚拟节点,映射到虚拟节点上其实就是存储到其对应的真实节点中
- 特点
没有set/delete的方法,只提供了get方法,
- 如何解决缓存穿透/缓存雪崩/缓存穿透
- 缓存穿透
采用了singleflight,一个并发控制的方法,避免同一时间对某个key请求,然后发起n个对数据源的请求,这个方法用了一个map进行存储,key是对某个key的调用,value的话是一个请求发起,然后用waitgroup进行控制,然后每个请求会先查询map是否存在该key,如果存在则进行等待,等待第一个执行完后直接从call里获得对应的值,如果不存在则创建一个
- 缓存雪崩
从数据源里读出来的没有过期时间,就没有雪崩问题,而手动通过缓存预热接口加入的才存在过期时间,这一部分需要用户自定义超时随机时间来处理
关于服务器宕机问题的话,就是添加了恢复和预热策略,避免刚恢复或启动就接收了大量请求而去读取数据源
- 缓存穿透
读到一些不存在的会缓存对应的空值,然后设置一个较短的过期时间
- 读写缓存穿透,以及其余缓存策略
-
读写缓存穿透
-
旁路缓存
-
异步缓存
-
介绍一下对分布式的了解
-
缓存预热
节点新上线时可以直接加载一批缓存进入,然后存入该节点的热点缓存中,因为存入的接下来是很可能会用上的,但是存在问题就是如果加载进来的缓存是错误的,在过期时间之前不会执行读写穿透 -
如何做上线数据恢复和转移
首先为什么需要这个功能,我们用一致性哈希就存在这个问题,比如目前有两个节点a和b,在哈希槽中加入,然后对应的key=xiaoming此时经过一致性哈希分配到了节点b,这时又有一个节点c上线了,那么key=xiaoming此时经过一致性哈希却分配到了节点c上,那么如果去进行查询的话又需要再一次从数据源中加载,那么如果是大量的类似key出现这种情况,全加载到了一个节点上,那么有可能使得节点宕机,所以可以的话会考虑在上线时,在加入哈希槽时,顺便找到他的下一个位置的节点,然后从该节点复制一定量的数据加载到当前节点中,这样虽然会有一定量的数据冗余,但是能以防刚上线时由于没有缓存存在而直接类似缓存雪崩的情况
恢复的话目前其实还是转移功能,而宕机前的数据还无法恢复,因为没有备份机制,备份机制的话目前的想法是设置备份节点,然后定时任务,每隔多久就去获得一定量的值同步到同步节点中,而在同步间隙的期间,就会使用一个数组来存储entry类型,然后定时同步到另外一边去,上线的时候也要设置好同步节点,然后从该节点的备份数据加载过来
- 协商填充
还是一致性哈希,key和节点之间的绑定
- 热点缓存
缓存一些不属于本节点的key
为了避免缓存源和数据不一致,热点缓存同步普通缓存的时间加上随机的一点时间并存储在请求节点,加上这点时间是为了使得热点缓存比普通缓存晚过期,否则可能出现热点缓存已经过期了,然后又同步了普通缓存过来,热点缓存恢复了,但是普通缓存又过期了的情况。
热点缓存的策略就是随机数/8,如果请求数量够多就有足够的概率变为热点缓存,当然还提供了手动设置功能,但是为了保证一致性,还是尽量少使用
- 还存在的问题
节点宕机了,则有可能大量请求打到另外一个节点上,然后需要重新从数据源加载
算法
LRU
最近最少使用,基于一个假设,算法认为最近被使用的数据很大可能接下来也会被访问到,所以LRU算法的核心思想是把最近访问的数据放在缓存的顶部,而最久未被访问的数据放在缓存的底部,当缓存已满,则替换底部的数据,即最近最少使用的数据,实现方法可以是哈希表和双向链表
二叉树
满二叉树:所有的节点的度只有0或者2,并且度0的节点都在同一层
完全二叉树:除了最底层节点可能没满,其余每一层节点数达到最大,而且底层节点都集中在该层最左边的位置
深度优先遍历 - 前序遍历 - 中左右 - 中序遍历 - 左中右 - 后序遍历 - 左右中 广度优先遍历 - 层次遍历
递归
三要素:
- 确定递归函数的参数和返回值
- 确定终止条件
- 确定单层递归逻辑
双指针
- 使用条件:
单调
前缀和
可以把子数组的和转为sum[right+1]-sum[left],其中sum是前缀和,即前缀和的差
动态规划
最长递增子序列(LIS)
动态规划解法
最长子序列有一个特点:尾巴元素一定是这个序列的最大元素,如果已知一个递增序列和其尾巴元素,向他追加一个值更大的元素,构成的新的子序列也是递增序列。
所以我们可以看成动态规划的一种,dp[i]看成以i为尾巴元素的最长递增子序列,dp[i]为dp[j]+1,j为上一个小于i的最长子序列的尾部的位置
二分查找解法
BFS和DFS
BFS
广度优先算法,核心思想是把问题抽象成图,从一个点出发,向四周开始扩散,一般来说,都是采用队列来处理的。
BFS相对DFS来说,找到的路径一定是最短的,但是付出的代价会比较大。
代码:
golangtype Node struct { Val int Neighbors []*Node } func BFS(root *Node) { // 切片来模拟队列 queue := []*Node{root} visited := make(map[*Node]bool) visited[root] = true for len(queue) > 0 { // 出队 node := queue[0] queue = queue[1:] // 处理当前节点 // 一般就是判断有没有到达终点 // 遍历邻居 for _, neighbor := range node.Neighbors { if !visited[neighbor] { // 标记为已访问 visited[neighbor] = true // 入队列 queue = append(queue, neighbor) } } } }
如果是判断最短路径的次数,那么就要记录深度,在for里面不是每次出一个节点,而是获得当前队列的长度,并出队对应的长度,即一次循环出队一层,这样for循环执行的次数即找到最短路径的次数
golangfor len(queue) > 0 { for i:=0;i<len(queue);i++{ node := queue[0] // 后续一样 } // 记录次数 depth++ }
- 双向BFS
起点和终点同时开始,在有交集的时候停止
本文作者:Malyue
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!